
Insight #114_Sora, DevDay 2025, TML, 웹 비즈니스, 에이전틱 커머스, Rubin CPX, 메모리 반도체, AMD, AI 인프라 게임, 옵티머스, Figure, 네이버-두나무, Tempo, 스테이블코인
매일마다 커지는 AI 투자 금액에 놀라고 또 놀라는 요즘입니다. 덕분에 연휴가 즐거웠네요 (!)
오늘은 AI, 반도체, 인프라, 하드웨어, 핀테크, 투자에 대해 다룹니다.
뉴스레터 외에도 텔레그램 및 블로그에서 저의 생각을 접해보실 수 있습니다.
#오리지널
연휴라서 가볍게 남겨보는 아카이브 🙂
#AI
Sora 2가 공개되었는데, 모델이 발전한 것도 의미있지만 소라를 개별 앱으로 출시했다는 측면이 훨씬 더 중요해보인다.
아마도 트래픽이 엄청날텐데 이걸 버텨낼 수 있다는 자신감 또한 대단해보이고, 왜 데이터센터 건설에 집중하는건지도 이해가 된다.
OpenAI에게는 ChatGPT 이후로 가장 성공한 프로젝트가 되어가고 있는 Sora인데, OpenAI가 Sora 앱을 제대로된 SNS로 키우려는 야심을 보여주기 시작한다. 이거 기대보다 판이 커질 수도 있어보이는걸?
“영상 생성에 대한 수익 모델이 필요해졌습니다. 예상보다 사용자 1인당 영상 생성량이 훨씬 많으며, 소수의 시청자를 대상으로 생성되는 영상도 상당합니다. 이에 따라, 사용자가 특정 캐릭터를 생성할 때 해당 캐릭터의 권리자와 수익을 공유하는 방식을 시도할 예정입니다. 구체적인 모델은 시행착오를 거쳐 정해지겠지만, 곧 시작할 계획입니다.”
Introducing Vibes: A New Way to Discover and Create AI Videos
최근에 메타는 Meta AI에 Vibes라는 새로운 AI 비디오 전용 피드를 런칭했는데, Sora와 Vibes 중에 누가 더 파급력이 클지 지켜보는 것도 흥미롭다. 지금까지는 Sora가 Vibes에 비해 압승이긴 한듯.
Meta Vibes, Good Vibes, Vibes Vision - Stratechery
참고로 벤 톰슨은 Vibes가 AI 비디오만 모여져있다는 측면에서 이를 메타버스로 연상시키더라. 그리고 이는 메타가 취할 수 있는 좋은 전략이라고 보는 듯 하고.
OpenAI’s Windows Play - Stratechery
OpenAI의 DevDay 2025를 보면 OS가 되고자 하는 야심이 보이던데, 현재 OpenAI는 AI 시대의 최종 주인공 기업이 될 길을 너무나도 착실하게 걸어가고 있는 것 같다. 샘 알트만은 이 시대의 빌게이츠가 맞는듯.
“플랫폼이 되기 위한 경로는 먼저 대중적으로 폭발적인 인기를 얻는 제품이 되는 것이다. 개발자와 사용자를 확보하는 것은 ‘닭이 먼저냐 달걀이 먼저냐’의 문제가 아니다. 먼저 사용자를 확보해야 개발자가 따라오고, 그렇게 플랫폼이 선순환 구조에 들어간다. 다시 말해, 먼저 제품이 사용자들을 ‘집결(Aggregate)’시켜야 하며, 그 후 개발자들이 자연스럽게 따라온다.”
“ChatGPT를 미래의 운영체제로 만들기 위한 움직임이다. 앱은 더 이상 스마트폰이나 브라우저에 존재하지 않을 것이다. ChatGPT 안에 존재할 것이고, 거기에 없다면 ChatGPT 사용자들에게는 존재하지 않는 것이 된다. 이는 곧, 이러한 통합과 전환 성능을 보장할 책임이 OpenAI가 아닌 서드파티 개발자들에게 돌아간다는 의미다. 사용자 소유에서 오는 힘이며, OpenAI는 이 힘을 본격적으로 행사하고 있다.”
“OpenAI가 생태계에서 중요한 소프트웨어 레이어가 된다면 Nvidia의 장기 가격 결정력은 약화될 것이다. Nvidia는 여전히 칩 성능과 저수준 락인을 통해 막대한 이익을 가져가겠지만, OpenAI가 이 거래를 추진하는 가장 중요한 이유는 자신의 지배적 위치를 스택 내에 고착화하기 위해서다. 이 발표가 Nvidia의 OpenAI 투자 후 몇 주 만에 나왔다는 점은, 사용자를 가진 기업이 궁극적인 권력을 쥔다는 또 하나의 증거다.”
“AI의 Windows가 되려는 이 전략은 OpenAI를 AI 빌드아웃 전체의 핵심축(linchpin)으로 위치시킨다. OpenAI와의 파트너십 발표만으로도 Oracle과 AMD의 주가가 어떻게 반응했는지 보라. OpenAI는 AI 버블의 중심에 자신을 위치시키는 조건을 만들어가고 있으며, 이는 이 공간으로 유입되는 투기적 자본의 최대 수혜자가 된다는 뜻이다. 현재 상황에서는 버블이 터지기 전까지 원하는 만큼 자금을 조달할 수 있을 것으로 보인다.”
“그리고 흥미롭게도, OpenAI-Microsoft의 패턴에서 Apple의 자리는 현재 Google이 차지하고 있다. 칩부터 데이터센터, 모델, 최종 사용자 배포 채널까지 완전 통합 스택을 보유하고 있다. 그러나 Google은 다양한 경쟁자들과 싸우는 대신, 원하든 원하지 않든 OpenAI를 중심으로 점점 더 통합된 생태계와 맞서고 있다. 이것이 바로 수요 집결(Aggregation)과 ChatGPT 현상의 힘이다.”
An Interview with OpenAI CEO Sam Altman About DevDay and the AI Buildout - Stratechery
샘 알트만은 YC에서 투자자로 일하면서 배운 ‘자본배치’ 능력이 사업하면서 큰 도움이 된다고 말한다. 내가 그는 엄청난 수준의 인프라 건설을 해낼 수 있다고 보는 이유.
“(당신은 실리콘밸리 역사상 최고의 자금 조달자 중 한 명으로 오랫동안 여겨졌죠. 그 능력이 이 분야에서 이 정도로 중요하게 작용하리라고 미리 알았나요?)”
“커리어 초기에 배운 것들이 있었어요. 잘하게 됐다고까지는 못 하겠고, 그럭저럭 괜찮은 수준이었는데, 그게 나중에 OpenAI를 운영해야 하는 데 그렇게 좋은 준비가 될 줄은 몰랐습니다. 그런데 매우 도움이 되더군요.”
“제가 만약 제게 타고난 재능이 있는 일을 했다면, 저는 운영자가 아니라 투자자가 되었을 겁니다. 저는 여러 면에서 큰 회사를 운영하기에는 극도로 준비가 되어 있지 않지만, 투자자로서의 훈련과, 이런 미친 지수적 성장이 가능한 세상에서 자본 배분을 어떻게 생각해야 하는지에 대한 프레임워크를 정말로 이해하는 능력을 갖추고 있습니다. 마법을 여러 번 보았고, 프로젝트와 사람을 어떻게 선택하고, 이런 세상에서 자본을 어떻게 배분해야 하는지를 생각하는 방법 말이죠.”
“어떤 의미에서는 OpenAI가 일련의 스타트업에 베팅하고 있는 셈인데, 그들은 모두 내부적이거나 때로는 ‘소라(Sora)’ 같은 제품일 수도 있습니다. 그건 특이했어요. 저는 그게 회사를 운영하는 데 좋은 훈련이 될 거라고 생각하지 않았습니다. 사실, 아마 나쁠 거라고 생각했는데, 유용한 것으로 판명되었습니다. 여기 있는 모든 것들에 대해 한 회차를 통째로 할애할 수도 있겠지만, 그게 또 다른 예입니다.”
샘 알트만은 다 계획이 있다는데, 나는 그의 말을 최대한 믿어야한다고 생각한다.
“(조금 더 자세히 들어가서, 놀라웠던 계약 중 하나는 삼성 및 SK하이닉스와의 계약이었습니다. 분명히 메모리는 미래에 이러한 칩을 구축하는 데 있어 큰 제약인데, 이것이 AMD 계약과 관련이 있는 건가요? 사람들이 가졌던 질문 중 하나는 “AMD가 이 칩에 들어갈 메모리를 어디서 구할 것인가?”였는데, 아니면 여전히 자체 칩을 만들고 계신 건가요?)”
“몇 달만 시간을 주시면 모든 것이 이해가 될 것이고, 전체에 대해 이야기할 수 있을 겁니다. 저희는 보기만큼 미치지 않았습니다. 계획이 있습니다.”
Sora 관련 코멘트
“세상에는 잠재적인 창의적 표현에 대한 수요가 너무나 많아서, 만약 당신이 사람들에게 그것을 조금 더 잘할 수 있도록 돕는 도구를 준다면 — 아마도 구식 방식으로 훌륭한 틱톡 비디오를 만들거나 무엇을 하기가 정말 어려울 수 있지만, 만약 당신이 사람들에게 아이디어에서 창의적인 결과물로 빠르게 나아갈 수 있게 해주는 도구를 준다면, 그것은 매우 깊은 인간의 욕구를 건드리고, 저는 그것이 계속해서 성공하는 것을 보아왔습니다.”
“처음부터 우리에게 분명했고, 우리가 이것을 하게 되어 흥분했던 이유 중 하나이며, 이것이 단지 무의미한 슬롭 피드(slop feed, 저품질 콘텐츠)처럼 느껴질 것이라고 생각하지 않았던 이유는, 우리가 창작의 활성화 에너지를 극적으로 낮출 수 있다면, 평소에 창작하는 것보다 훨씬 더 많은 사람들이 그것을 할 것이라고 희망했기 때문입니다. 그리고 며칠 동안 숫자를 보지 않았지만, 첫 며칠 동안 활성 사용자 중 30 몇 퍼센트가 활성 창작자였는데, 정말 놀라웠습니다.”
사람들이 ChatGPT를 사용하는 방법에 대해서 연구한 자료.
아직까지는 ‘구글’과 유사한 목적으로 사용하는 경우가 많아보이는데, 아무래도 지금은 이 세상 모든 사람들이 AI를 어떻게 사용하면 좋을지 알아가는 시기인듯.
3~5년 뒤 똑같은 연구를 하면 직장에서의 사용률이 증가함으로 인해서 크게 다른 연구 결과가 도출될 것 같다.
“이 연구는 OpenAI의 경제 연구팀과 하버드 경제학자 David Deming이 수행한 National Bureau of Economic Research(NBER) 작업 논문으로, 150만 개의 대화에 대한 대규모 개인정보 보호 분석을 통해 ChatGPT 출시 이후 소비자 사용이 어떻게 진화했는지 추적합니다. 샘플 크기와 주간 활성 사용자 7억 명을 고려할 때, 이는 AI의 실제 소비자 사용에 대해 발표된 가장 포괄적인 연구입니다.”
“AI의 민주화를 진행하면서 사용 격차가 좁혀지고 있습니다. 2025년 중반 기준으로, ChatGPT의 초기 성별 격차는 극적으로 좁혀졌으며, 채택은 일반 성인 인구와 유사하게 나타났습니다. 2024년 1월, 이름이 남성적이거나 여성적으로 분류될 수 있는 사용자 중 37%가 전통적으로 여성적인 이름을 가지고 있었습니다. 2025년 7월에는 이 비율이 절반을 초과(52%)하게 되었습니다.”
“또한, ChatGPT는 저소득 및 중간소득 국가에서 특히 빠르게 성장하는 전 세계적으로 접근 가능한 도구가 되었습니다. 2025년 5월 기준으로, 가장 낮은 소득 국가에서의 ChatGPT 채택 성장률은 가장 높은 소득 국가의 4배 이상이었습니다.”
“ChatGPT의 소비자 사용은 대부분 일상적인 작업을 수행하는 데 집중되고 있습니다. 대화의 3분의 2는 실용적인 조언을 구하거나 정보를 찾거나 글을 작성하는 것에 집중하고 있으며, 글쓰기가 가장 흔한 작업이지만, 코딩과 자기 표현은 여전히 틈새 활동으로 남아 있습니다.”
“사용 패턴은 ‘질문’, ‘실행’, ‘표현’의 측면으로 나눠 볼 수 있습니다. 대화의 약 절반(49%)은 “질문”으로, 사람들이 ChatGPT를 작업 완료뿐만 아니라 조언자로서 가장 가치 있게 사용하고 있음을 보여줍니다. ‘실행’ (사용의 40%, 그 중 약 3분의 1은 직장 관련)은 텍스트 작성, 계획 또는 프로그래밍 등과 같은 작업 지향적인 상호작용을 포함하며, 여기서 모델은 출력 생성이나 실용적인 작업 완료를 위해 사용됩니다. ‘표현’(사용의 11%)은 질문이나 실행과는 다르며, 보통 개인적인 반성, 탐색 및 놀이가 포함됩니다.”
“ChatGPT의 경제적 영향은 직장과 개인 생활 모두에 확장됩니다. 소비자 사용의 약 30%는 직장 관련이고 약 70%는 비직장 관련으로, 두 범주 모두 시간이 지나면서 계속 성장하고 있습니다. 이는 ChatGPT가 생산성 도구이자 소비자에게 일상 생활에서 가치를 창출하는 역할을 하는 이중적인 역할을 하고 있음을 강조합니다. 일부 경우, 이는 전통적인 GDP와 같은 지표가 포착하지 못하는 가치를 생성하고 있습니다.”
“가치 창출의 핵심 방법은 의사결정 지원입니다. ChatGPT는 특히 지식 집약적인 직업에서 판단력과 생산성을 개선하는 데 도움을 주며, 사람들이 이러한 이점을 발견함에 따라 사용은 더 깊어지고 있습니다. 사용자 그룹은 시간이 지나면서 개선된 모델과 새로운 사용 사례 발견을 통해 활동을 늘리고 있습니다.”
Cognition | Rebuilding Devin for Claude Sonnet 4.5: Lessons and Challenges
이번에 앤트로픽이 새로운 모델인 Claude Sonnet 4.5을 공개했는데 (이전 모델이 7시간동안 스스로 코드를 작성할 수 있었다면, 이번 모델은 30시간까지 늘어났다는게 포인트), 저번에 윈드서프 인수해서 화제가 된 Devin이 새로운 모델에 맞게끔 제품을 ‘Rebuilding’ 했다고 발표했다.
이 내용이 중요한 이유는 새로운 모델이 나오면 그 모델을 사용하는 프로덕트가 그냥 저절로 좋아지는게 아니라, 나름대로의 노력이 필요하다는 이야기이기 때문이다. 즉, 생각 이상으로 AI 프로덕트를 만들고 운영하는 것이 어려울 수 있다는 이야기.
Sora the App, Sonnet 4.5 and the Question of Models as Processors - Stratechery
이에 관한 벤 톰슨의 의견도 같이 남겨둔다.
“지난 몇 년간 내가 고민해온 큰 질문 중 하나는 모델의 진화가 1980~1990년대 프로세서의 진화와 유사할지 여부였다. 당시 소프트웨어 개발에 접근하는 최선의 방법은 현재 보유한 프로세서의 한계까지 밀어붙여 코드를 작성하는 것이었다. 그러면 여러분이 코드를 완성하거나 그 직후에 고객들은 새로운 프로세서를 얻게 되어, 모든 느린 코드가 빨라지는 동시에 기본적인 동작은 거의 동일하게 유지되었다.”
“AI 모델들이 — 많은 면에서 새로운 프로세서라 할 수 있는 — 유사한 경로를 따른다면, AI 애플리케이션을 개발하는 최선의 방법은 현재 모델의 능력 한계까지 밀어붙여 개발하고, 새로운 모델이 이전 모델과 거의 동일하지만 사실상 모든 측면에서 더 나아진 채로 나타날 것이라는 자신감을 가지는 것이다. 이렇게 하면 애플리케이션은 단순히 API 타겟을 교체하는 것만으로 성능 향상을 수확할 수 있다. 이는 특정 틈새와 사용 사례에 집중할 수 있고, AI 모델의 개선을 거의 추가 비용 없이 누릴 수 있는 풍요로운 세계를 앱 개발자들에게 제공한다.”
“그러나 코그니션은 이것이 반드시 사실이 아닐 수도 있다는 데이터를 제시했다: 그들의 그래프를 보면 새 모델이 일부 벡터에서 실제로 성능이 떨어졌음을 알 수 있다. 새로운 모델의 장점을 진정으로 활용하기 위해 코그니션은 애플리케이션을 완전히 재구축해야 했다.”
“물론 데빈 같은 앱은 모델의 동작과 관련해 “메탈에 매우 가까운” 수준에 있기 때문에, 더 평범한 앱들은 차이를 느끼지 못할 수도 있다. 동시에, 이는 AI 앱 개발자가 예상보다 훨씬 어려울 수 있다는 증거이기도 하다: 이전 투자가 그만큼 가치가 없을 수 있으며, 이는 곧 훨씬 더 높은 지속적인 R&D 비용으로 이어진다. 한편으로 모델 자체는 단순히 사용자의 비즈니스를 직접 잠식할 수 있는 더 많은 기회를 갖게 될 것이다.”
Defeating Nondeterminism in LLM Inference
무라티의 Thinking Machines Lab 블로그에 글이 하나 올라왔는데, 어떤 기술을 만들고 있는지 꽤나 상세하게 서술하고 있다.
쉽게 이야기하면 AI를 실행할 때 마다 매번 결과가 조금씩 달라지는 현상을 고치려고 하며,
이는 원래는 ‘GPU가 동시에 많은 계산을 하다 보니 숫자 더하는 순서가 달라져서 그렇다’라고 설명되지만, 실제로는 서버 상황에 따라 묶이는 요청의 크기가 달라지고 그때마다 계산 방식이 달라지기 때문에 결과가 달라지는 것이라고 규명하고 있다.
그래서 TML은 AI의 핵심 연산(정규화, 행렬 곱셈, 어텐션)을 다시 설계해서 어떤 상황에서도 숫자가 같은 순서로 더해지고 곱해지도록 하여 매번 같은 결과가 나오게끔 모델을 설계하고 있다고 한다.
상당히 흥미로운 문제 인식이라고 생각하는데, 근데 이거 다른 모델 개발사들도 꽤나 금방 따라할 수 있는거 아닌가 하는 우려도 동시에 든다. 과연 TML의 운명은...?
무라티의 스타트업, 첫 제품으로 ‘미세조정용 API’ 출시 - AI타임스
이어서 미세조정용 API인 Tinker라는 제품을 공개했다. 최종 결과물을 내놓기 전 중간 결과물이겠지만, 그럼에도 불구하고 초기 투자받은 밸류에 비해서는 임팩트가 약하긴 한 것 같네.
The YouTube Tip of the Google Spear - Stratechery
AI의 ‘어플리케이션’ 관점에서 현재 가장 뚜렷한 진전을 보이는 영역 중 하나가 광고 영역이라고 생각하는데, 구글은 유튜브라는 엄청난 광고 채널을 가지고 있고 이제 여기에 AI를 활용하기 시작했다는 주장. 매우 설득력이 있다.
“유튜브 영상 속 모든 아이템이 수익화 가능한 표면으로 변하고 있다. 이렇게 노골적으로 말하면 디스토피아적으로 들릴 수 있지만, 실제로는 이득이 크다. 나는 최근 집수리 영상을 많이 보는데, 영상 속 장비들을 바로 확인하고 구매할 수 있으면 정말 편리하다. 대부분 배경에만 나와 있는 장비인데도 말이다. 머지않아 유튜브는 이런 인벤토리를 확보하게 될 것이고, 이를 제휴 링크로 제공하거나 입찰 방식으로 기업이 고객에게 노출할 수 있도록 할 것이다.”
“더 일반적으로 보면, 구글이 이걸 해낼 수 있는 그림이 보인다. 챗봇 시대의 시작은 최악이었지만, 이제 구글은 스스로를 추스르고 모델·인프라 리더십을 바탕으로 실행하고 있다. 반면 메타는 벽에 부딪혀 AI 접근 방식을 완전히 다시 짜야 했다. 물론 마크 저커버그가 해결책을 찾긴 하겠지만, 지금 당장은 구글 — 놀랍게도! — 이 실제 제품을 내놓고 있다.”
“내가 AI 시대 구글에 대해 가졌던 걱정은, 회사가 광고주를 위한 경매를 통해 막대한 경제적 이익을 창출했던 방식 대신, “답변 기계”가 되려는 과정에서 그 이익을 잃을 수 있다는 점이었다. 하지만 그것은 어디까지나 텍스트 기반 세상이다. 장기적으로는 그게 영상 세계만큼 중요하지 않을 수도 있다. 다시 말해, 구글은 검색에서 내가 예상했던 것보다 더 잘하고 있고, 클라우드 사업에 AI가 미치는 영향에도 나는 항상 낙관적이었다. 그러나 내가 놓쳤던 부분은, 구글이 이미 자사의 AI 우월성을 폭발적으로 발휘할 창 끝을 갖고 있다는 점이다. 바로 유튜브. 눈앞에 숨은 거인이자, 동시에 상상할 수 없을 만큼 크지만 이제 막 시작한 사업이다.”
클라우드플레어의 Matthew Prince가 AI로 변화를 맞이하고 있는 웹 지형도를 바라보는 관점. 결국 웹의 인터페이스가 검색에서 답변으로 바뀌고 있고, 이에 따라서 새로운 비즈니스모델이 탄생할 것이라는 전망.
개인적으로는 그가 구글을 바라보는 관점이 인상적이었다. 그는 구글을 너무 잘 이해하고 있어서, 이번의 변화가 더욱 명확하게 다가오는 것 같다.
“지난 25년 동안, 인터넷의 인터페이스는 검색이었고, 구글이 그 공간을 지배해왔습니다. 그리고 구글의 회사로서의 인센티브는 인터넷을 가능한 한 많이 성장시키는 것이었습니다. 왜냐하면 혼돈이 있을 때, 검색이 그 혼돈의 조직자가 되기 때문입니다. 하지만 사람들이 실제로 콘텐츠를 만들도록 하는 인센티브가 필요했고, 그래서 구글은 인터넷을 조직하는 것을 만들어야 했을 뿐만 아니라, 사람들이 가는 곳의 트래픽을 가져와서 사람들이 그것을 수익화하도록 돕는 것을 만들어야 했습니다. 주로 광고를 통해서였지만, 구독도 도왔죠. 그리고 구글은 지난 25년 동안 인터넷의 위대한 후원자였습니다. 만약 구글 같은 것이 없었다면 웹은 지금과 같은 모습으로 존재하지 않았을 겁니다. 트래픽을 중심으로 인센티브를 주는 것에는 많은 문제가 있었습니다. 우리는 사람들이 광고를 붙이기 위해 클릭하게 하려고 말 그대로 분노를 유발하는 헤드라인을 만들려고 하는 시스템을 만들었습니다. 그래서 완벽하지는 않았지만, 구글과 검색이 자금을 대지 않았다면 오늘날 우리가 가진 인터넷은 없었을 겁니다.”
“그것이 변하고 있습니다. 세상은 웹의 인터페이스가 검색 엔진에서—검색 엔진은 당신에게 보물 지도를 주고 “이 10개의 파란색 링크를 클릭해서 답을 찾아보세요”라고 말합니다—효과적으로 답변 엔진으로 바뀌고 있습니다. 그래서 OpenAI를 보면, Anthropic을 보면, Perplexity를 보면, 심지어 현대의 구글을 보면, 그들은 검색 엔진이 아닙니다. 그들은 당신에게 보물 지도를 주지 않습니다. 대신, 그들은 그 페이지 맨 위에 바로 답을 줍니다. 그 답은 대부분의 사용자에게, 95%의 사용자에게, 95%의 경우에 더 나은 사용자 인터페이스입니다. 저는 답변 엔진에 반대하지 않고, AI에 반대하지 않습니다. 저는 우리 모두가 상호 작용하는 인터페이스가 그렇게 되는 것이 모든 가능한 면에서 더 낫다고 생각합니다.”
“(Q. 하지만 문제는 당신이 답을 얻고 보물 지도를 얻지 못하면, 트래픽을 생성하지 않는다는 것입니다. 그리고 트래픽을 생성하지 않으면, 트래픽에 기반해 온 웹의 전체 비즈니스 모델이 무너지기 시작합니다. 그리고 그것을 볼 수 있습니다. 이커머스 사이트에서는 그렇게 많이 보이지 않고, 실제로 물리적인 것을 파는 것들에서도 그렇게 많이 보이지 않습니다. 왜냐하면 만약 당신이 어떤 카메라를 사는 것이 가장 좋은지 물었다면, 답을 얻더라도 어딘가에서 사야 하기 때문입니다. 이커머스와 물건을 파는 사람들은 괜찮을 것이지만, 리뷰를 쓴 사람은— 물리적 제품의 위대한 점은 정의상 희소하다는 것이고, 인터넷상의 텍스트의 문제는 그것이 희소하지 않다는 것입니다.)”
“희소하지 않죠, 정확히 맞습니다. 그리고 구글은 모든 사람이 인터넷을 무료로 스크랩할 수 있다는 기대를 만들었지만, 그것은 결코 무료가 아니었습니다. 인터넷은 결코 무료였던 적이 없습니다. 구글이 아주 오랫동안 그 비용을 지불했고, 콘텐츠 제작자들과의 암묵적인 합의는 “우리는 당신의 콘텐츠 사본을 얻고, 그 대가로 당신에게 트래픽을 보내주고 그 트래픽을 수익화하는 것을 도와주겠다”는 것이었습니다. 그 암묵적인 합의는 우리가 검색 엔진에서 답변 엔진으로 전환하면서 무너집니다. 그래서 무언가 변할 것입니다.”
“우리가 새로운 비즈니스 모델을 찾아내는 것입니다. 그리고 그것은 AI 회사들, 즉 거기에 있는 답변 엔진들이 창출하는 수익의 일부가 콘텐츠 제작자들에게 돌아가는 어떤 형태여야 합니다. 그리고 그것이 어떻게 작동하는지는, 다시 말하지만, 우리가 알아내려고 노력하고 있는 것입니다.”
“월간 활성 사용자(MAU)당 연간 1달러를 AI 회사들이 콘텐츠 제작자들에게 분배되는 풀에 넣는다고 생각할 수 있습니다. 계산을 해보면, 오늘날 콘텐츠 측면에서 약 100억 달러에 해당하는데, 이는 오늘날 담장 안의 정원(walled garden)이 아닌 인터넷에서 생성되는 모든 광고 수익을 완전히 대체할 수 있는 금액입니다. 그러니까 인스타그램, 페이스북, 틱톡 그리고 그런 것들을 제외한 (구글 네트워크, 트레이드데스크 등과 같은 것들이요) -> 하지만 월스트리트 저널, 뉴욕 타임스, 파이낸셜 타임스, 레딧, 그 외 모든 것을 포함하면 연간 약 100억 달러입니다. 그건 많은 돈이지만, 미친 듯이 많은 돈은 아닙니다. 그리고 만약 우리가 그것을 해결할 수 있다면, 우리는 실제로 더 나은 비즈니스 모델을 만들 수 있고, 만약 우리가 그것을 제대로 한다면, 저는 그것이 실제로 더 나은 미디어와 더 나은 콘텐츠가 동시에 만들어지도록 장려한다고 생각합니다.”
“다시 말하지만, 클라우드플레어와 상관없이, 저는 여전히 출판사들이 “좋아, 우리는 봇들이 우리 콘텐츠에 접근하는 것을 차단하고, 그 다음에 가장 독특한 콘텐츠를 위한 시장을 만들 것이다”라고 말하는 것이 당연하다고 생각합니다. 그리고 그것이 더 독특할수록, 더 많은 돈을 받게 될 것이라고 생각합니다. 그것은 그냥 당연합니다.”
Buy it in ChatGPT: Instant Checkout and the Agentic Commerce Protocol
OpenAI는 Stripe와의 협력으로 ‘Agentic Commerce Protocol’을 정의하고 Instant Checkout라는 즉시 결제 시스템을 개발했다. 에이전트 커머스의 영역으로 직접 진출하겠다는 의미이자, OS에 필요한 요소들을 하나씩 구축해나가는 모습으로도 볼 수 있겠다.
사실 나는 AI 기반의 커머스에 대해서 회의적이었는데 (왜 필요한지 명확한 이유가 보이질 않았다), 이를 검색의 관점에서 생각해보니 새로운 가능성이 보이는 것 같기도 하다. 검색의 여러 목적 중 하나는 나의 문제를 해결해줄 상품을 찾는 것이 분명히 포함되고, 이 관점에서 ChatGPT는 매우 훌륭한 해결책을 보여주고 있기 때문에 커머스까지 연결지으면 이 검색의 파이는 꽤나 많은 부분을 가져갈 수 있을 것으로 보인다.
즉, OpenAI는 계속해서 검색의 점유율을 높이려는 시도를 하고 있다고 나는 해석했다.
Announcing Agent Payments Protocol (AP2) | Google Cloud Blog
관련해서 구글 클라우드에서 에이전트 결제를 위한 AP2 프로토콜을 공개했다. 이는 스테이블코인을 포함한 여러가지 결제 형태를 지원한다고 한다.
AI 에이전트 시대가 다가오다보니 이를 위한 결제 프로토콜을 선점하기 위한 움직임들 또한 계속해서 나타나는 것 같은데, 결국 이러한 시도들이 모여서 완전히 새로운 인터넷의 모습을 형성하게 될 것 같다.
검색의 시대가 저물고, AI 에이전트의 시대가 열린다 - Chester Jungseok Roh
이걸 카카오가 해낼 수 있냐는 것과는 별개로, 먼 미래에 이걸 다시보면 맞는 말이었네 할 가능성이 높을 것 같다. 무엇보다도 OpenAI 자체가 이런 방향성으로 나가려는 모습을 계속해서 보여주는 것 같고.
(그리고 실제로 OpenAI는 DevDay 2025에서 동일한 방향성을 보여주었다.)
“정신아 대표의 메시지는 나에게 이렇게 들렸다. “카카오의 핵심 경쟁력은 ‘관계의 연결’이다.” 이 관계의 연결 위에 AI를 올려놓겠다는 전략. Kanana 라는 자체 AI와 OpenAI의 ChatGPT를 카카오톡에 직접 내재화시켜, 사용자들이 별도의 앱이나 사이트 방문 없이 대화창에서 모든 것을 해결할 수 있게 만들겠다는 것. 카카오톡이라는 관문(Gateway) 안에서 모든 정보 소비와 생산, 그리고 거래까지 가능하게 만들겠다는 너무나도 당연하지만 아직은 아무도 하지 않았던 일을 하고 있는 것.”
“이제 기업들은 자신들의 서비스를 AI 에이전트로 만들어 카카오톡에 연결할 수 있다. 피자집은 주문 에이전트를, 병원은 예약 관리 에이전트를, 쇼핑몰은 상품 추천 에이전트를 만들어 카카오톡 안에 심는다. 사용자는 카카오톡을 떠나지 않고도 “오늘 저녁 피자 주문해줘”, “다음 주 병원 예약 잡아줘”라고 대화하듯 모든 일을 처리할 수 있게 된다.”
“이것이 바로 AI 시대의 새로운 광고 모델이자 비즈니스 모델이다. 키워드 입찰로 트래픽을 유도하는 것이 아니라, 비즈니스를 AI 에이전트화해서 플랫폼에 직접 통합시키는 것. 카카오는 사용자와 서비스 제공자 사이에 새로운 형태의 GAP을 만들고, 이를 통해 수익을 창출하는 새로운 중간자가 된다.”
“Will AI be as big of a catalyst for a consumer AI wave as mobile?” - Sarah Tavel
‘모바일’은 새로운 폼팩터였기 때문에 사람들이 컴퓨터에 노출되는 시간 자체를 극적으로 끌어올렸고, 그에 따른 수많은 사업 기회들이 파생되었다.
하지만 AI는 시간을 두고 모바일과 경쟁해야하기 때문에, 시간을 뺏어온다는 관점에서는 모바일만큼의 사업 기회들이 등장하기는 어려울 것이다.
다만 반대로 AI는 소비자의 삶을 더 편하게 만들거나 새로운 능력을 부여해줄 수 있는 사업 기회는 훨씬 많이 생길 것이다.
결국 기술마다 나름의 특성이 있고, 이를 가장 잘 발현시킨 회사가 가장 큰 기회를 잡게 되는 것이다.
추가로) 이 내용을 GPT에게 넣어주고 본질을 탐구하게 하였더니:
“한 줄로 말하면, 소비자 AI의 본질은 ‘주의(분) 경제’가 아니라 ‘대행(Agentic)·과업완료 경제’로의 축 이동입니다.”
“모바일은 유휴 시간을 디지털로 흡수해 ‘분’을 폭발시켰고, AI는 (현재) 기존 분을 재배치하면서 반복 과업을 자동화·대행해 가치(지불의사)를 만든다는 점이 핵심 차이예요. 그래서 초반 승부처는 틱톡류와의 주의 쟁탈이 아니라 유틸리티·에이전트형 서비스(일·학습·구매·건강·가계정리·창작 등)입니다.”
“이 판을 바꾸는 트리거는 세 가지: (1) AI-네이티브 디바이스/보이스·웨어러블 보급, (2) OS·메신저의 백그라운드 권한 개방(분배), (3) 추론비용의 한 자릿수 배 하락. 이 셋이 겹치는 순간, ‘분’까지 커지며 모바일급 파장이 다시 열립니다.”
“따라서 지금 측정해야 할 지표도 DAU·체류시간보다 주당 완료 과업 수, 성공률, 유료전환/재구매입니다.”
China Releases “AI Plus” Policy: A Brief Analysis
중국의 ‘AI 플러스’ 전략의 목표는 AI 어플리케이션의 대중화. 즉, AI를 기술에 머물지 않고 실제로 실생활에 쓰이게끔 만들겠다는 것.
Step 1: 2027년까지. 6대 핵심 분야에서 광범위하고 심층적인 AI 통합을 달성한다. 차세대 지능형 단말기와 AI 에이전트의 사용률은 70%를 초과해야 하며, 지능형 경제의 핵심 산업 규모가 빠르게 성장해야 한다.
Step 2: 2030년까지. 지능형 단말기와 AI 에이전트의 보급률이 90%를 초과하고, 지능형 경제가 중국 경제의 주요 성장 동력이 될 것이다.
Step 3: 2035년까지. 중국은 본격적으로 지능형 경제와 지능형 사회의 새로운 단계로 진입하게 될 것이다.
How many digital workers could OpenAI deploy? - Epoch AI
현재 AI는 몇명의 인간 노동자를 대체할 수 있는가? 시간이 흐를 수록 숫자는 커질 수 밖에 없고, 그 숫자에 따라 세계 경제에 미치는 파급력은 기하급수적으로 커질 것이다.
이 글은 현재 OpenAI와 같은 기업들이 약 700만 명 규모의 디지털 노동자를 배치할 수 있는 하드웨어를 보유하고 있는 것으로 추산하였는데, 숫자 자체보다는 이 숫자를 계산한 근거가 상당히 흥미로웠다.
그리고 자연스럽게 ‘진짜로 당장 700만명의 사람을 대체할 수 있다면?’ 이라는 질문도 해보게 된다.
<선도 연구소들이 배치할 수 있는 디지털 노동자 수 추정하기>
그렇다면 이 700만이라는 숫자는 어디서 나온 걸까? 노동통계국(BLS) 웹사이트에 “AI 직원 수” 페이지가 있는 것도 아니다. 따라서 우리는 AI가 실제로 수행하고 있는 “작업량”을 추정해야 한다.
우리는 AIs가 매일 처리하는 토큰 수와 인간이 하루 동안 읽고, 생각하고, 쓰면서 “처리”하는 효과적인 토큰 수를 비교한다. 두 값을 나누면, 현재 AI가 해결할 수 있는 작업에서의 디지털 노동자 수가 나온다.
첫 번째 단계는 선도 연구소들이 하루에 처리하는 토큰 수를 계산하는 것이다. 구체적인 예로 OpenAI의 GPT-5를 살펴보자.
한 가지 방법은 OpenAI의 추론(inference) 컴퓨팅 예산을 보는 것이다. The Information의 보도에 따르면, OpenAI는 현재 약 48만 개의 H100 상당량의 칩을 보유하고 있으며, 이는 하루 약 10²⁵ FLOP(부동소수점 연산)을 처리할 수 있다. GPT-5가 토큰 하나를 생성하는 데는 대략 1000억~6000억 FLOP가 필요하므로, 하루 10조~100조 토큰 정도를 생성할 수 있다.
또 다른 접근법은 사용량 통계를 직접 보는 것이다. ChatGPT는 하루 약 40억 개의 메시지를 전송하는 것으로 추정된다. 만약 API 사용량이 ChatGPT 토큰의 1/4을 차지하고, 평균 메시지 길이가 4000 토큰이라면, GPT-5는 하루 약 20조 토큰을 생성하는 셈이다.
최종 계산에서는 이 두 가지 추정치를 혼합해, 불확실성을 반영한 신뢰구간을 적용했다. 그 결과 중앙값은 하루 약 19조 토큰이다. 이는 Google의 AI 모델들이 하루 35조 토큰을 생성한다는 추정치와 비교해도 상당히 근접한 수치다.
이제 토큰 수를 알았으니, 이를 “인간 노동자 당 하루 토큰 처리량”으로 나눠 디지털 노동자 수로 변환해야 한다.
<인간 노동자의 ‘토큰 처리량’을 기준으로 환산하기>
단순히 인간이 하루 동안 말하거나 쓰는 단어 수를 기준으로 할 수도 있다. 그러나 이는 인간이 실제로 생각에 사용하는 시간을 과소평가할 가능성이 크다. 따라서 **인간의 사고 속도(분당 380 단어)**를 기준으로 삼았다. 이를 토큰으로 환산하고, 하루 8시간 근무한다고 가정하면, 인간 노동자 한 명은 하루 약 24만 토큰을 처리한다.
단순 계산으로는 “GPT-5는 하루 19조 토큰을 출력하고, 인간은 1인당 24만 토큰을 처리하니 19조 ÷ 24만 = 8000만 디지털 노동자”라는 결과가 나온다. 하지만 이건 “GPT-5의 토큰 1개 = 인간의 토큰 1개”라고 가정하는 셈인데, 이는 사실이 아닐 수 있다.
그래서 대안 접근법으로 METR 연구를 참고했다. METR은 AI가 특정 소프트웨어 관련 작업(예: 버그 수정)을 수행하는 데 인간이 걸리는 시간과 비교하는 방식이다. 예를 들어, 어떤 작업을 인간 프로그래머가 한 시간에 해결한다고 하자. GPT-5가 동일한 작업을 처리하는 데 필요한 토큰 수를 계산하고, 이를 하루 8시간에 곱해 “인간 1명에 해당하는 하루 토큰 수”를 추정한다.
METR 연구에 따르면 GPT-5는 이런 작업을 해결하는 데 10만~100만 토큰을 사용한다. 하루 8시간으로 환산하면 80만~800만 토큰이다. 19조 토큰을 이 수치로 나누면, 약 240만~2400만 명의 디지털 노동자가 나온다.
이 두 접근법을 결합한 결과, 중앙값 추정치는 700만 명, 신뢰구간은 매우 넓다.
Founders Fund Shifts From Caution to Concentrated Bets on AI - The Information
피터틸이 파운더스펀드 주주총회에서 소수의 AI 기업들에게 집중투자 하겠다는 계획을 발표했다고 한다.
그는 작년에 2024년의 AI는 1999년의 인터넷과 유사하다며 버블을 경고한 바 있는데, 그럼에도 불구하고 소수의 기업들은 살아남아 독점력을 가질 것이라고 생각했을 것이다. 집중투자의 달인께서 이제 어느정도 씬에 대한 판단이 서신 모양.
참고로 그들이 투자한 AI 회사는 OpenAI, Cognition (Devin), Crusoe, General Matter가 대표적이다. 최근 OpenAI $300b 라운드에도 $1b 투자했다고 알려져있고.
Concentrating In Winners | Vince Hankes, Partner at Thrive Capital | Ep. 27
Thrive Capital 파트너인 Vince Hanke가 말하는 포폴사들 투자 이유
“Isomorphic은 구글 내부에서 시작됐습니다. Gemini를 이끄는 Dennis Hassabis의 두 번째 프로젝트 혹은 회사입니다. 그는 단백질 구조 예측에 관한 연구로 Snowball Prize를 받았습니다. 그 연구가 이제 이 회사로 발전했습니다. 회사의 전체 미션은 “모든 질병을 치료한다”입니다. 매우 거대한 미션이죠. 좋은 미션이기도 합니다. 우리 포트폴리오에서 OpenAI와 맞먹을 정도의 잠재적 규모를 가질 수 있는 몇 안 되는 회사 중 하나라고 생각합니다. 만약 그 미션이 가능해진다면, 수조 달러 규모의 시장이 열립니다. 그들의 목표는 모든 실험실의 ‘습식 실험(wet lab)’을 컴퓨터로 시뮬레이션하는 것입니다. 만약 그렇게 된다면, 신약 개발의 방식이 완전히 뒤집히게 됩니다. 기존의 waterfall 대신, 모든 것을 컴퓨터 상에서 실행하는 구조가 되는 것이죠.”
“하지만 제 생각에 데이터브릭스 투자에 있어서 가장 중요한 점은, 단일 제품 회사에서 다중 제품 플랫폼으로 전환하고 있다는 것이 분명해졌고, 플랫폼의 가치는 단일 제품의 가치보다 훨씬 크다는 것입니다. 그래서 본질적으로 가격이 잘못 책정된 것입니다. 왜냐하면 단일 제품보다 다중 제품 플랫폼을 구축하는 것이 훨씬 어렵기 때문입니다.”
“왜 우리가 Rogo에 흥미를 느꼈는가? 그것은 ‘사람’에서 시작합니다. 예를 들어, Gabe(창업자)는 제가 보기엔 12점 만점에 12점입니다. 정말 탁월하죠. 그리고 그 카테고리 자체도 흥미로운 특성을 가지고 있습니다. 개인적으로 저는 “데이터 비즈니스를 챗봇을 통해 노출하는 것”이 대규모 노동 시장을 공략하는 것보다 더 흥미로운 지점이라고 생각합니다. 그래서 저는 요즘 어떤 데이터 자산을 이런 방식으로 노출할 수 있을까에 집중하고 있습니다. 모델들이 거대한 데이터를 구조화하고 검색하는 데 놀라울 정도로 뛰어나기 때문입니다.”
AI Will Not Make You Rich - joincolossus
이번 AI 사이클에서 마지막 승자가 되기 위해서는 어느 구간에 비중을 크게 실어야할지, 그리고 어느 타이밍에 들어가고 나올 것인지 끊임없이 고민해야 할 것이다.
아래는 GPT에게 부탁한 글 요약:
이 글은 생성형 AI가 새로운 “부의 물결”을 만들 수 있을지, 아니면 기존 대기업과 소비자에게만 이익이 돌아가고 창업자·투자자에게는 큰 몫이 남지 않을지를 역사적으로 비교하는 논문형 에세이입니다.
핵심은 PC 혁명과 컨테이너화의 대비입니다. PC는 예기치 못한 수요와 분산적 실험이 터져 나오며 스타트업과 투자자에게 엄청난 부를 안겼습니다. 반면 컨테이너화는 세계 경제를 뒤바꿀 만큼 혁신적이었지만, 경쟁과 과잉투자로 수익성이 낮아져 창업자·투자자가 얻은 이익은 극히 제한적이었습니다. 글은 AI가 후자에 더 가깝다고 주장합니다.
AI는 이미 모두가 그 잠재력을 인지하고 있어 “놀라움”이 부족하며, 빅테크가 모델을 지배하고 실험 공간이 제한적입니다. 따라서 모델·앱 회사에 무턱대고 투자하기보다는, 소비자와 다운스트림 산업에 기회가 있다고 봅니다. 즉, AI로 생산성이 개선되는 지식집약 서비스(의료, 교육, 금융, 크리에이티브) 기업 중 비용 절감을 가격 인하와 볼륨 확대 전략으로 전환할 수 있는 곳이 승자가 될 가능성이 큽니다. 반면 인프라·데이터센터나 모델 회사는 이미 고평가되어 있으며, 성공해도 빅테크에 흡수될 리스크가 큽니다.
결론적으로, AI의 총가치는 크지만 투자자와 창업자가 얻을 초과이익은 제한적이고, 진짜 수혜자는 소비자가 될 가능성이 크다는 점을 강조합니다. 투자 전략은 “무엇이 새로운가”보다 “효율성이 열어주는 기회가 어디에 있는가”를 찾는 데 맞춰야 한다는 메시지입니다.
#반도체
NVIDIA Unveils Rubin CPX: A New Class of GPU Designed for Massive-Context Inference
Another Giant Leap: The Rubin CPX Specialized Accelerator & Rack - Semi Analysis
LLM 추론은 입력을 읽어 첫 토큰을 만드는 프리필(연산 집약·대역폭 덜 씀)과 이후 토큰을 뽑는 디코드(메모리 대역폭 집약) 이렇게 두 부분으로 나뉘는데, 지금껏 두 단계를 같은 HBM GPU로 처리하느라, 프리필 구간에서는 비싼 HBM 대역폭이 놀고 TCO(총비용)가 낭비되었다고 한다.
이번에 공개된 Rubin CPX는 프리필에 특화된 단일 가속기로, HBM 사용량과 비용 비중을 크게 낮추고 & NVLink 같은 스케일업 네트워킹 비용도 절감시켜서 → 결과적으로 토큰 단가에서 큰 우위를 확보했다고 한다.
그냥 심플하게, 엔비디아가 추론에 최적화된 솔루션을 선보였다고 보면 된다. 역시나 항상 앞서가는 엔비디아.
삼성 HBM4와 1c D램 현황은 어떨까 - 강해령의 테크앤더시티
삼성전자가 드디어 엔비디아 HBM3E 퀄 테스크를 통과했다는 소식이 들려오는데, 내부에서는 당연히 HBM4에 사활을 걸고 있다고.
아직 HBM4에 들어가는 1c D램의 수율이 높지 않은 상황이지만, 돈을 버는 것 보단 일단 넣는게 중요하다는 판단인가보다.
“현재까지 삼성전자가 HBM4에 쓸 1c D램의 수율은 콜드 테스트 기준 35% 전후로 파악됩니다.”
“SK하이닉스의 1c D램 수율은 상반기에 이미 80%를 넘겼습니다. 1b D램 및 HBM 시황과 타이밍을 보고 양산 설비를 구축하고 있는 단계죠.”
“양사의 설비 투자 흐름을 보면 내년은 확실하게 HBM4와 1c D램의 시대가 될 것 같습니다.”
“최대 월 120만장인데”...오픈AI, 삼성·SK에 HBM용 D램 90만장 요청
샘 알트만은 한국에 찾아서 디램 90만장 공급을 요청. 삼성전자 하이닉스가 합쳐서 120만장 정도의 캐파를 가지고 있으니 저 숫자가 사실이라면 OpenAI 만으로도 75%나 차지한다는 소리.
아래는 메모리 반도체 관련해서 내가 이런저런 생각을 메모한 내용 (주의: 추정이 들어갔기에 사실과 다를 수 있습니다.)
<HBM>
그동안은: 엔비디아 GPU에 HBM에 쓰이기 시작했고, 이걸 하이닉스가 독점 공급하면서 하이닉스 시대가 열렸다.
HBM의 이익률은 50~60%로 일반 DRAM의 30%보다 훨씬 높고
각 HBM 칩은 특정 AI GPU 칩에 맞게 설계되어야 하기 때문에, 생산 1년 전에 주문이 이뤄져야 하며 일반적으로 1년 단위로 계약을 진행된다. 따라서 HBM은 기존의 디램/낸드와는 다르게 팹리스 기업과 유사하다.
덕분에 하이닉스는 약 2년간 돈을 쓸어담았다.
삼성전자와 마이크론이 엔비디아에 HBM을 넣기 위해 고군분투하였고, 결국 이제서야 들어가는 느낌이다.
마이크론이 먼저 HBM3E 8단 넣기 시작했고, 12단 또한 퀄 통과한 것으로 알려졌다.
삼성전자 또한 AMD에 이어서 결국 엔비디아에 HBM3E 12단 넣기로 확정되었다.
HBM4가 진정한 전쟁터가 될 것으로 보이는데, 현재까지는 삼성, 하닉, 마이크론 모두 납품할 것으로 보인다.
삼성전자가 (상대적으로 수율이 낮은) 1c 디램을 통해서 퀄을 통과할 예정이라고. 그만큼 진심이다.
마이크론은 성능이 낮아서 납품이 어려울 것이라는 우려와는 다르게 좋은 성능을 뽑아내며 가능성이 커졌다.
그리고 DDR5 가격 상승이 HBM 가격 협상에 직접적인 지렛대로 작용해서, ASP 하락 우려가 줄어듬
“HBM이 DRAM을 잡아먹는다”는 과거의 우려가, ‘DRAM이 HBM을 지탱한다”는 새로운 시각으로 전환
→ 하이닉스 독점 포지션이 깨질 것 같고, 당분간 HBM으로 인한 수혜는 닉스보다는 삼전과 마이크론이 더 클 예정
→ 그럼에도 불구하고 HBM 수요가 지금보다 훨씬 커질 것이기에 3사 모두 행복할 것이라고 생각됨
<DRAM>
모두가 HBM에 집중하느라 디램 투자는 제한되었고, 자연스럽게 디램 공급이 부족해지기 시작했다.
26년에 삼전 P4, 하닉 M15x Phase1은 HBM4를 위한 투자
27년에 삼전 P5, 하닉 용인 Y1이 준공되어서야 캐파 증가가 가능함
최근 DRAM 시장이 수요 개선 없이도 공급 타이트로 가격이 두 자릿수(q/q 10% 이상) 상승하기 시작
→ HBM으로 인해서 디램 공급 축소가 일어나면서 디램의 가격이 구조적인 상승이 일어나기 시작한 것
여기서 샘 알트만은 월 90만장에 이르는 디램 공급을 요청했다 (!!!)
현재 삼성전자의 전체 D램 생산능력(CAPA; 캐파)은 월 60만~65만장으로 추산된다. SK하이닉스는 월 50만장 수준이다. 마이크론은 월 30만장 정도.
따라서 120만장 정도의 캐파인데, 여기서 90만장이면 75%나 달라는 소리다.
= 스타게이트만 전 세계 DRAM 생산량의 거의 40%를 차지할 것
→ 공급이 부족해서 가격 상승이 일어났는데, 앞으로는 수요까지 폭증하네? 말도 안되는 숫자로…?
<SSD>
AI가 데이터를 워낙 많이 생성해내고, 더불어서 멀티모달로 진화하면서 데이터 스토리지의 중요성이 계속해서 증가하고 있다.
우선 기업들은 HDD를 찾았던 것 같은데, 구할 수 있는 HDD가 부족해지자 SSD까지 찾기 시작한 모양이다.
그리고 원할한 서비스의 제공을 위해서라도 기업들은 SSD를 찾을 수 밖에 없다. 속도가 차원이 다르니.
eSSD 시장 현재 1위는 삼성, 2위는 SK하이닉스 (3위 마이크론, 4위 키옥시아, 5위 샌디스크)
지난 2분기에 eSSD 쪽에서 닉스가 +47%QoQ의 압도적 매출성장을 보이면서 M/S 26.7% 기록(+5.9%P vs 1Q25)
M/S 3.9%인 샌디스크의 현 시총은 $20b
→ 웨스턴디지털 & 씨게이트의 상승을 샌디스크가 9월부터 한방에 따라잡았으며, 이 추세는 더욱 가팔라지는중
<멀티플>
AI 덕분에 HBM이라는 새로운 아이템에 디램 & 낸드까지 사이클이 찾아온 상황.
메모리 시장의 수요 곡선 자체를 근본적으로 바꾸는 구조적 변화의 신호탄으로 해석하기 시작.
역사상 가장 강하고 긴 메모리 사이클이 찾아온다는 이야기가 나오기 시작한데 이어서,
메모리는 더이상 시클리컬 산업이 아니라 ‘장기 고성장산업’으로 변화하고 있다는 소리까지 나오기 시작
→ 모건스탠리는 마이크론 타겟 PER 22배로 설정하며 이를 반영하기 시작
→ 삼성전자와 하이닉스에 같은 논리를 대입하기 시작하면, 메모리는 이제 시작이 아닐까…?
NVIDIA and Intel to Develop AI Infrastructure and Personal Computing Products
인텔과 엔비디아의 딜은 아래와 같은 내용을 담고 있는데, 왜인지 나는 엔비디아가 더 득을 보는 것 같다 (시장은 인텔에 환호했지만).
인텔은 아키텍처에 NVLink를 통합해, 특히 기업 시장에서 NVLink를 이더넷의 훨씬 더 신뢰할 만한 대안으로 만든다.
인텔은 엔비디아 시스템에서 사용할 맞춤형 x86 칩을 설계할 것이다. 현재 엔비디아 시스템은 모두 엔비디아가 설계한 ARM 칩을 사용한다.
인텔은 인텔 CPU와 엔비디아 GPU를 통합한 칩렛 기반 시스템온칩(SOC)을 판매할 것이다.
Nvidia and Intel, Tan’s Earnings Call Negotiation, Deal Specifics - Stratechery
그리고 재미있는 관점들:
“이번 거래에서 가장 큰 패자는 TSMC가 아니라 AMD다. AMD는 2006년 ATI 인수 덕분에 x86 CPU뿐만 아니라 GPU에서도 인텔과 경쟁한다는 차별성을 오래 유지해왔다 (ATI는 당시 엔비디아의 가장 큰 경쟁자였다). 그러나 불행히도 AMD는 소프트웨어에 능숙하지 못했고, 엔비디아가 구축한 AI 소프트웨어 스택을 만들지 못했다. 또한 엔비디아가 가진 네트워킹 능력도 없다. 이는 CPU와 GPU 사업을 모두 보유한 것이 가질 수 있었던 가치를 충분히 실현하지 못했음을 의미한다. 이제 엔비디아 GPU와 x86 CPU를 동시에 원하는 회사들에게 명확한 1순위 선택지가 생겼으며, 그 인텔 CPU에는 AMD가 가지지 못한 또 하나의 독점 기술이 탑재될 것이다.”
“주목할 점은 이번 거래가 인텔 팹에서 엔비디아 AI 칩을 만드는 것이 아니라는 점이다. 인텔은 이번 거래의 칩과 아마도 다른 엔비디아 제품들에 대해 패키징 작업을 더 많이 얻게 될 것이다. 인텔의 패키징은 상당히 진보되어 있지만, 최첨단 칩 제조와는 직접 관련이 없다. 그럼에도 엔비디아는 도움을 주고 있다. 50억 달러와 장기적 약속은 회사에 대한 신뢰의 표시이며, 인텔이 필요로 하는 고객을 다른 누군가가 맡을 가능성을 높인다. 결국, 이것이 아마도 이번 거래의 가장 영리한 부분일 것이다. 미국-인텔 거래 이후, 모든 대형 팹리스 반도체 회사들이 인텔 지분을 취득하고 거래를 제공하라는 압박을 받을 가능성이 크다. 엔비디아는 먼저 움직여, 자사 사업에 실제로 유용한 거래를 성사시켰고, 동시에 아무도 원하지 않는 인텔 제조에 직접적으로 약속하지 않아도 되었다.”
AMD and OpenAI announce strategic partnership to deploy 6 gigawatts of AMD GPUs
OpenAI가 총 6GW 규모의 AMD 칩을 구매하겠다는 파트너십을 발표. 이 과정에서 AMD는 OpenAI가 주당 1센트에 지분 10%를 인수할 수 있는 조건부 계약을 채결.
AMD는 칩 팔 수 있어서 좋고, OpenAI는 싸게 칩 수급할 수 있어서 좋고, 엔비디아 의존도를 줄일 수 있는건 덤.
#인프라
OpenAI, Oracle, and SoftBank expand Stargate with five new AI data center sites
OpenAI는 추가 데이터센터 부지를 공개하면서 스타게이트 프로젝트의 확장을 공식화했다. 세 곳은 오라클, 두 곳은 소프트뱅크와 함께하는 구조.
처음에 스타게이트 프로젝트가 발표될 때만 하더라도 이게 말이되나 싶은 숫자였는데, 이제는 진짜가 되어가고 있다. OpenAI의 거대한 인프라 프로젝트가 속도가 붙는 모습.
“7월에 OpenAI와 Oracle은 최대 4.5기가와트의 추가 Stargate 용량을 개발하기 위한 협약을 체결했습니다. 이는 향후 5년 동안 양사 간 3,000억 달러를 초과하는 파트너십을 의미합니다. 세 곳의 신규 부지—텍사스주 샤켈퍼드 카운티, 뉴멕시코주 Doña Ana 카운티, 그리고 곧 발표할 예정인 미드웨스트 지역의 한 부지—에 더해, 텍사스주 애빌린의 플래그십 Stargate 부지 인근에서의 600메가와트 추가 확장 가능성을 합치면, 5.5기가와트를 넘는 용량을 제공할 수 있습니다.”
“오늘 발표되는 나머지 두 곳의 Stargate 부지는 향후 18개월 동안 1.5기가와트까지 확장될 수 있습니다. 이들 부지는 여러 기가와트 규모의 AI 인프라로 확장 가능한 SoftBank와 OpenAI의 파트너십을 통해 개발될 예정입니다.”
샘 알트만의 최근 우선순위는 누가 봐도 AI 인프라 확장인데, 이에 대한 샘 알트만의 생각은 다음과 같다:
“만약 우리가 컴퓨팅에 의해 제한된다면, 우리는 무엇을 우선시할지를 선택해야 할 것입니다. 그 선택을 하고 싶어하는 사람은 아무도 없으니, 그러지 않도록 만들기 위해 우리가 해야 할 일은 바로 인프라를 구축하는 것입니다.”
“우리의 비전은 간단합니다: 우리는 매주 1기가와트의 새로운 AI 인프라를 생산할 수 있는 공장을 만들고자 합니다. 이를 실행하는 것은 매우 어려울 것입니다. 이 이정표에 도달하려면 몇 년이 걸리고, 칩에서부터 전력, 건축, 로보틱스에 이르기까지 모든 수준에서 혁신이 필요할 것입니다. 그러나 우리는 이에 대해 열심히 작업해왔으며, 이는 가능하다고 믿습니다. 우리의 생각으로는, 이것은 가장 멋지고 중요한 인프라 프로젝트가 될 것입니다. 우리는 특히 이 인프라를 미국에서 많이 구축하는 것에 대해 매우 흥분하고 있습니다. 지금 다른 나라들이 칩 팹이나 새로운 에너지 생산 시설을 우리보다 훨씬 빠르게 구축하고 있기 때문에, 우리는 그 흐름을 뒤집는 데 기여하고 싶습니다.”
“향후 몇 달 동안 우리는 이 계획과 이를 현실로 만들기 위해 함께 일하고 있는 파트너들에 대해 이야기할 예정입니다. 올해 후반에는 이를 어떻게 자금을 조달할 것인지에 대해서도 언급할 것입니다. 컴퓨팅을 늘리는 것이 수익 증가의 열쇠라는 점에서, 우리는 몇 가지 흥미로운 새로운 아이디어를 가지고 있습니다.”
OpenAI and NVIDIA announce strategic partnership to deploy 10 gigawatts of NVIDIA systems
그럼 돈은 어디서 나오는가? 바로 이렇게!
엔비디아가 OpenAI에 수년간 $100b를 투자하여 최소 10GW 데이터센터를 건설하겠다고 발표.
예전부터 AI는 결국 컴퓨팅 인프라 게임으로 흘러갈 것 같다는 생각을 자주 공유하곤 했었는데, 요즘의 뉴스들이 그걸 증명하고 있는 것 같다.
In OpenAI Megadeal, Nvidia Discusses a New Business Model: Chip Leasing - The Information
관련해서 엔비디아는 반도체를 임대해주는 방식으로 OpenAI에게 칩 공급을 고려 중이라고.
인프라에 천문학적인 금액이 투자되고 있다보니 투자 수단 또한 다양화되고 있는 모습이다.
Nvidia Steps Back From Cloud Effort to Compete with AWS - The Information
엔비디아는 계속해서 자체적인 클라우드 사업을 확장하려는 모습을 보여주고 있는데, 이로 인해서 AWS를 비롯한 하이퍼스케일러 업체들이 경각심을 가지고 자체적인 인프라를 구축하는데 더욱 진심이 되는 모양이다.
지금 당장은 마소 애저가 너무 잘나가고 있어서 AWS가 평가절하되는 이야기가 많이 보이는데, 장기적으로 아마존은 자기 할일을 잘 해낼 것이라고 본다. 아마존이야야 말로 전세계에서 비용 컨트롤을 가장 잘하는 회사가 아닌가.
Amazon’s AI Resurgence: AWS & Anthropic’s Multi-Gigawatt Trainium Expansion - Semi Analysis
OpenAI가 오라클을 통해 데이터센터를 늘리는 것 처럼, 앤트로픽은 AWS 통해서 컴퓨팅 파워를 확보하고 있다 (앤트로픽 전용 데이터센터를 건설 중).
그리고 이 과정에서 아마존의 ASIC인 Trainium2가 핵심적인 역할을 하고 있고, NeuronLinkv3라는 새로운 스케일업 네트워크 또한 도입하는 중이라고.
Oracle Pops, From Databases to AI, Oracle and OpenAI - Stratechery
오라클의 진짜 강점은:
“오라클은 클라우드 전환이 늦어 AWS에 데이터베이스 시장 점유율을 빼앗기기 시작했다. 회사는 기존 고객에게 최적의 솔루션을 제공하는 것이 추격의 최선의 방법임을 깨달았다. 즉, Exadata를 클라우드에서 제공하고 SmartNIC, 이더넷, RDMA까지 그대로 구현하는 것이다. 고객은 기존 오라클 시스템을 OCI로 “리프트 앤 시프트”만 하면 온프레미스와 동일한 성능을 얻을 수 있다.”
“이 모든 것은 LLM이 등장하기 전에 일어난 일이지만, 아이러니하게도 오라클은 LLM 학습에 필요한 요건(저지연, 결정론적 성능, 대규모 확장성)에 가장 잘 준비된 클라우드 사업자가 되었다. 특히 RDMA와 네트워킹 최적화는 오라클이 오랫동안 집중해온 분야였다. 늦게 클라우드에 진입한 것이 오히려 LLM에 최적화된 클라우드를 만드는 계기가 된 것이다.”
“그러나 오라클이 만들지 않은 것이 있다. GPU도, 모델도 없다. 대신 OCI는 일종의 AI 인프라의 TSMC다. TSMC 창업자 모리스 창은 대만의 유일한 강점이 반도체 제조였음을 깨닫고 순수 파운드리 모델을 택했다. 이는 업계 전체가 신뢰할 수 있는 집합적 해법이 되었고, 오늘날의 TSMC를 만들었다.”
“오라클 역시 LLM 중립성을 가진다. 즉, 자체 모델을 만들지 않아 모델 사업자 입장에서 신뢰할 수 있는 파트너다. 더 중요한 점은, 다른 클라우드 사업자들과 달리 자체 칩을 만들지 않고 엔비디아에 올인했다는 것이다. 이는 네트워크가 엔비디아에 최적화되어 있을 뿐 아니라, 엔비디아가 가장 선호하는 고객 중 하나가 되게 했다. GPU 수요가 공급을 초과하는 상황에서 엔비디아는 자신을 대체하지 않는 고객(즉 오라클)에게 우선 공급할 가능성이 크다. 덕분에 오라클은 다른 클라우드보다 안정적으로 최신 GPU 공급을 확보할 수 있었다.”
Internal Oracle Data Show Financial Challenge of Renting Out Nvidia Chips - The Information
최근 오라클이 적자 보면서 클라우드 돌리고 있다는 보도가 나오면서 일시적으로 급락했는데, 나는 이런 코멘트를 남겼다:
“공장하고 똑같은걸로 보는데요, 공장을 처음 건설하자마자 수익이 나는게 아니잖아요? 가동률이 올라와야 제대로 돈을 벌기 시작하는건데, 이제서야 GPU 돌리기 시작한 것이기 때문에 시간이 흐를수록 돈을 제대로 벌기 시작하지 않을까 싶습니다.”
CoreWeave - Goldman Sachs Communacopia + Technology Conference

내가 과거에 코어위브를 공부하면서 ‘이 회사의 본질은 ‘리스’업, 금융 비즈니스다’라는 메모를 적어두었다. 지금도 그 생각은 변함이 없다.
“용량과 올바른 제품이 아무리 많아도, 자금을 조달할 수 없다면 작동하지 않습니다. 그리고 그 세 변수 중, 파이낸싱 측면이 우리의 비즈니스가 계속 가속할 수 있게 하는 데 얼마나 결정적인지에 대해 가장 과소평가되어 있다고 생각합니다.”
“(더 긴 기간, 더 큰 계약은 재무 관점에서 무엇을 가능하게 합니까? 어떤 자금 조달 기회가 열립니까?) 우리가 접근할 수 있는 자본의 트랜치 풀이 계속 확장됩니다. 우리의 초점은 투자등급(investment grade)입니다. 그것이 우리가 대차대조표와 리스크 익스포저를 관리하는 데 있어 북극성(North Star)입니다. ‘어떻게 그걸 달성할 것인가’죠. 지난 12개월 동안, 우리는 비투자등급(non-IG) 자본 비용을 900bp 이상 낮췄습니다.”
#하드웨어
As Elon Musk Preps Tesla’s Optimus for Prime Time, Big Hurdles Remain - The Informaion
올해 옵티머스 로봇을 수천대 양산하겠다는 계획이 뒤로 밀렸다고 한다. 이유는 ‘손’ 기능 구현에 어려움을 겪고 있어서 이것부터 해결하는걸 우선순위로 잡았다고.
뭔가 자율주행에서 ‘카메라만으로 가능하다 vs 라이다가 합리적이다’로 맨날 의견 충돌해온 것 처럼, 로봇에서는 손을 두고 비슷한 논의가 이어질 것 같다는 느낌적인 느낌이 드는군. 그리고 결국 머스크가 채택한 방식이 (비록 시간은 오래 걸리겠지만) 더 합리적일 것 같고... 역사는 반복되니.
Figure Exceeds $1B in Series C Funding at $39B Post-Money Valuation
로봇 스타트업 Figure가 무려 $38b 밸류로 $1b 투자 유치에 성공했다고.
개인적으로는 이게 맞나 싶을정도로 밸류가 높아보이기는 한다. 휴머노이드 분야가 핫하긴 핫하군...
이어서 Figure는 새로운 휴머노이드 모델을 발표. 새로운 촉감 센서를 바탕으로 손 기능 개선에 집중한게 눈에 띈다.
Robotics Startup Physical Intelligence in Talks to Raise at $5 Billion Valuation - The Information
투자자가 화려해서 팔로업 하고 있는 로봇 스타트업 Physical Intelligence은 무려 $5b 가치로 투자 유치 중이라고 (시드 투자자만 해도 Khosla Ventures, Lux Capital, OpenAI, Sequoia Capital, Thrive Capital)
아직 실체가 드러난게 별로 없어서 이야기할께 많이 없긴 한데, 이 분야가 얼마나 핫한지만큼은 확실히 알 수 있겠다.
#핀테크
[단독] 확 바뀌는 네이버 지배구조…두나무 송치형 최대주주로 - 한국경제
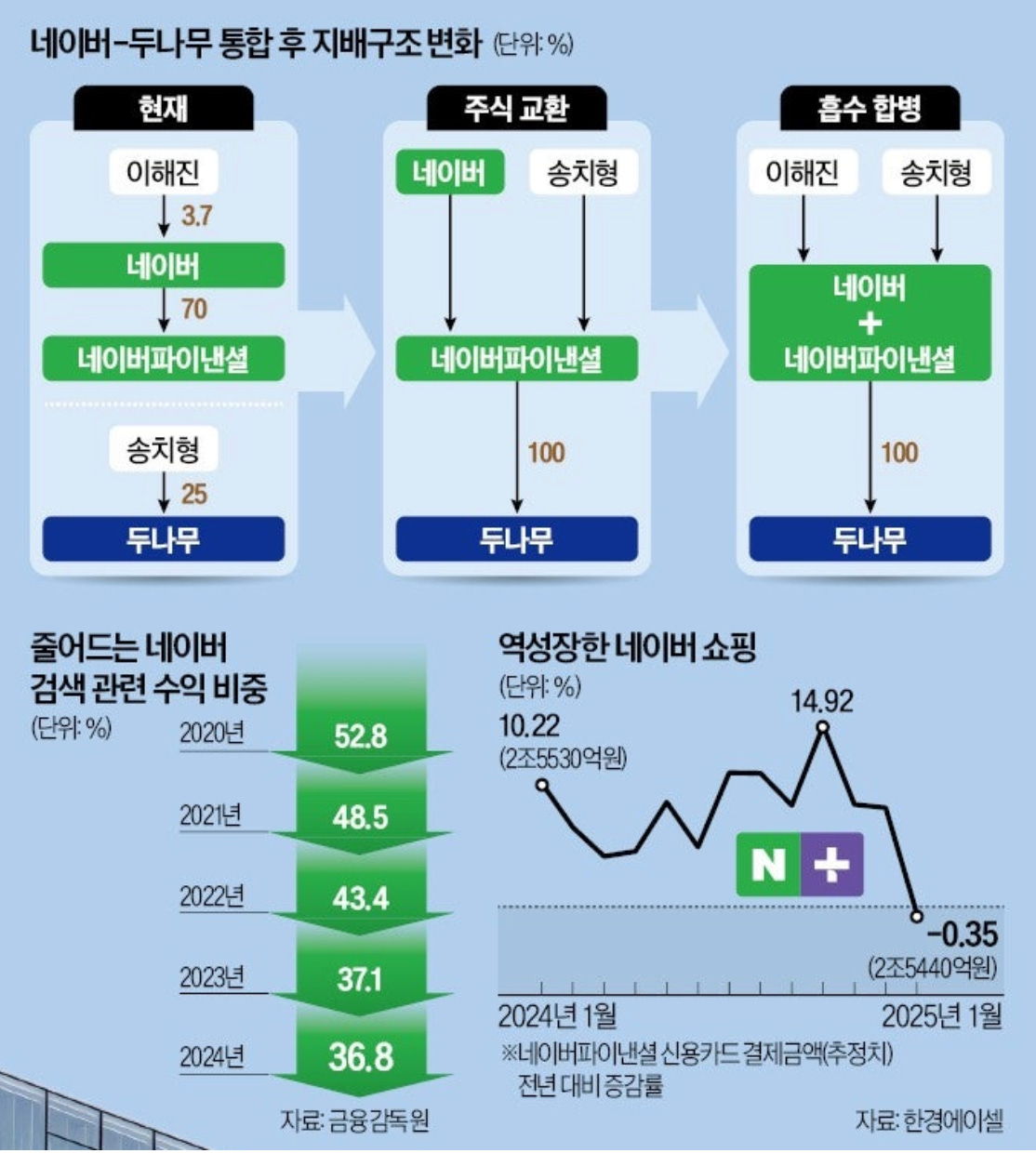
네이버는 창업 1년 뒤인 2000년에, 당시 돈을 벌고 있었던 김범수의 한게임과 합병을 한다. 이는 지금의 네이버를 존재하게 한 가장 결정적인 순간 중 하나다. 나는 이번 딜에서 비슷한 모습이 보이는 것 같다.
[단독] 이해진의 빅픽처…송치형 앞세워 ‘넥스트 네이버’ 예고
“이해진 네이버 이사회 의장은 수년 전부터 사석에서 가깝게 지내온 송치형 두나무 회장과 장병규 크래프톤 의장에게 네이버와의 합병을 수차례 제안했다. 1차적으로는 네이버에 부족한 암호화폐와 게임사업을 대형 인수합병(M&A)으로 단숨에 보완하겠다는 전략이었지만, 이면에는 네이버의 미래 리더십에 대한 고민이 깔려 있었다. 이 의장은 맨땅에서 각자의 그룹을 일궈낸 창업자들이 네이버 생태계에 합류해 상호작용하며 동력을 불어넣는 것이 네이버가 나아가야 할 방향이라고 확신했다.”
“네이버와 두나무 간 ‘빅딜’은 이 의장의 제안을 송 회장이 수용하면서 급물살을 탔다. 서울대 컴퓨터공학과(옛 전자계산기공학과) 선후배 사이로 막역한 두 수장이 공감대를 형성하자 양측은 곧바로 태스크포스(TF)를 꾸려 절차에 착수했다. 초기 구상은 네이버 본사와 두나무 간 지분 교환이었다. 하지만 두나무가 올해 초 금융정보분석원(FIU) 제재 등으로 당국의 감시 대상에 오른 데다 상장사인 네이버 주주들의 동요 가능성까지 감안해 무산됐다.”
“대안으로 제시된 것이 자회사인 네이버파이낸셜을 활용한 단계적 통합 방식이다. 양측은 두나무와의 주식 교환 이후 네이버와 네이버파이낸셜의 합병을 전제로 세부 조건을 조율 중이다. 송 회장이 우선 네이버파이낸셜의 경영을 총괄하며 그룹 내 입지를 다진 뒤 네이버와 네이버파이낸셜 간 합병 또는 추가적인 주식 교환을 통해 네이버 주식을 대거 확보할 수 있는 구조를 제안했다.”
Ramp at $1 Billion - Not Boring
Ramp를 보다보면 스트라이프 모습이 많이 보인다. 고객의 시간을 벌어다주는 중요한 제품을 연속적으로 선보일 수 있음을 증명하고 있는 기업이라는 점에서.
Tempo: Stripe’s Blockchain for Stablecoin Payments - Insight4vc
스트라이프가 패러다임과의 협업을 통해 개발중인 자체 L1 블록체인 ‘Tempo’를 공개했다. 스트라이프가 스테이블코인을 위한 결제 전용 체인을 만드는 것.
이전에 인수를 통해 확보한 Privy (지갑/키 관리 솔루션) & Bridge (스테이블코인 발행 및 liquidity API)에 이어서 자체적인 블록체인 구축까지 나아가면서 풀스택 인프라를 구축해나가고 있는 스트라이프다.
최근에 두나무가 스테이블코인을 위해 자체 L2 기와체인을 발표한 것과도 겹쳐보인다.
The stablecoin duopoly is ending - nic carter
스테이블코인은 테더와 써클이 양분하는걸로 당연하게 생각할 수 있지만, 사실 스테이블코인에게 네트워크 효과는 미미하며 새로운 경쟁이 열릴 수 있다고 주장하는 글.
솔직히 이 둘의 지위가 쉽게 꺾이는걸 현재는 상상하기 어렵긴 한데, 완전히 불가능한 시나리오는 아닌 것 같아서 한번 공유해본다. 실제로 최근들어 의미있는 새로운 스테이블코인이 계속해서 등장하고 있는 것도 사실이니.
“나는 과거엔 네트워크 효과가 승리할 것이라 믿었고, 결국 1~2개의 스테이블코인만 남을 거라 생각했다. 하지만 지금은 그렇게 보지 않는다. 체인 간 스왑은 점점 효율적으로 개선되고 있고, 체인 내 스테이블코인 간 스왑도 거의 비용이 들지 않는다. 1~2년 안에 대부분의 암호화폐 중개기관들은 예금을 “USDC”나 “USDT”가 아닌, 단순히 “달러”나 “달러 토큰”으로 표시하고, 사용자가 원하는 스테이블코인으로 상환을 보장하는 방식으로 바뀔 것이다.”
“현재 테더/서클 이외의 스테이블코인 공급량은 사상 최고이며, 발행사들도 다양해졌다. 흥미로운 점은 이들 신규 발행사 다수가 ‘수익 공유’를 핵심으로 삼고 있다는 것이다. GENIUS 법안은 직접 수익 지급형 스테이블코인을 금지하지만, 발행사가 중개기관을 통해 간접적으로 지급하는 것은 금지하지 않는다.”
“스테이블코인은 이제 겨우 10년 된 산업이다. 경쟁은 이제 시작이다.”
Introducing Robinhood Ventures
로빈후드가 비상장 회사들의 지분을 보유하는 Robinhood Ventures Fund I을 RVI라는 종목 코드로 상장시켜서 거래시킬 계획이라고 발표.
약간 스페이스X 간접투자 방식 중 하나인 Destiny Tech100 Inc (NYSE: DXYZ)와 유사한 모습이 되지 않을까 싶네.
토큰 증권도 그렇고, 비상장 회사들에 대한 리테일 접근성을 늘리는 것에 진심인 로빈후드인데, 이런 흐름들로 인해 장기적으로는 Private과 Public 시장의 경계가 상당히 허물어질 것 같다.
금융위 “비상장주식·조각투자 장외거래소 제도권 편입” - 파이낸셜 뉴스
한국에서도 사실상 비상장 주식 거래가 상장 주식 거래와 다를 바 없어지겠네. 네이버-두나무가 증권플러스 비상장으로 어떤 플레이할지 기대된다.
“이번 제도화의 핵심은 비상장주식 및 조각투자 장외거래소 영업을 위한 전용 투자중개업 인가단위를 각각 신설한다는 점이다. 기존에 자본시장법은 투자중개업자의 장외 증권 중개를 1:1 방식으로 제한했지만, 앞으로 ‘다수의 매수자와 매도자를 동시에 중개’하는 장외거래소 영업이 가능하다.”
#투자
“현재는 매크로가 냉각되며, 증시는 불안의 벽을 타고 오르고 있다. 소비와 밀접한 관련이 있는 실업률은 불안을 자극한다. 하지만 다른 한편으로는, 향후 몇년간 전개 될 변화에 대해 담대한 상상력을 가지고 이를 바탕으로 인류 역사상 몇 없던 변화기에 베팅할 수 있는 중대한 시기이기도 하다. 밸런스가 필요한 시기다.”
나는 투자자로 산 덕분에 확률론적인 관점으로 세상을 바라볼 수 있게 되었고, 여기에 있어서 미래를 남들보다 (아주 조금) 더 잘 내다볼 수 있는 나의 능력이 내 생각보다 훨씬 강력한 무기라는걸 점차 알아가고 있는데,
이 글이 정확히 같은 이야기를 하고 있다고 생각한다. 그래서 오늘 여러번 읽었다.
“결국 우리는 매일 수많은 크고 작은 의사결정을 하는데 이러한 것들이 각자 일종의 경로의존성을 갖고 상보적으로 영향을 주며 우리의 삶에 깊은 영향을 끼친다는 것이다. 하지만 우리는 시간이 지나서야만 과거 선택의 결과를 어렴풋히 이해할 수 있을 뿐이다.”
“미래를 정확하게 안다는 것, 또 대부분의 시장평균지능보다 1~2%의 확률 우위를 갖는 것은 중장기적으로 엄청난 격차를 불러일으킨다. 무언가를 정확하게 예측했다면, 이를 믿고 시간을 태우는 것이 인간이 할 수 있는 최소한의 겸손인것 같다는 생각이 드는 요즘이다.”
#마지막으로
Letter #300: Stan Druckenmiller and Jeff Feig (2009) - A Letter a Day
드러켄밀러 왈:
“저를 멘토링했던 사람은 분석 그 자체보다, 주가를 오르게 하고 내리게 하는 게 무엇인지에 대해 더 많이 가르쳐줬습니다. 전체 기능의 90%가 거기에 달려 있지만, 전체 사람 중 10% 정도만 그것에 집중한다고 봅니다.”
“그는 “왜 독립해서 하지 않죠?”라고 물었고요. 저는 “27살이고, 솔직히 돈이 없습니다”라고 했습니다. 그러자 그가 “그럼 제가 당신에게 매달 1만 달러를 줄게요. 그냥 당신과 대화하기 위해서요. 리포트 안 써도 됩니다—아무것도요. 그냥 대화에 대해 월 1만 달러를 주겠습니다”라고 하더군요. (~) 어쨌든, 그가 매달 1만 달러를 주겠다고 했고, 은행을 통해 저를 알던 몇몇이 90만 달러를 맡겼습니다. 1% 관리보수에 성과보수는 없으니 연 9천 달러죠. 합쳐서 12만9천 달러—제가 벌던 것보다 많았습니다. 최악의 경우 망해도 뉴욕에 와서 은행에서 일할 수 있겠다고 생각했습니다. 그렇게 시작됐습니다.”
“무언가가 당신에게 유리하게 갔을 때, 단지 기분이 좋아지려고 이익을 취하면 안 됩니다. 원래의 게임 플랜, 원래의 논지—A에서 B로 간다면, B가 어디인지—그걸 기억해야 합니다.”
“저는 분산투자가 정말 과대평가됐다고 봅니다. 진심입니다. 제 철학은 이렇습니다: 정말 훌륭한 논지를 갖고 있고 리스크/리워드를 분석했다면, 달걀을 몇 개 바구니—혹은 한 바구니—에 몰아 담고, 그 바구니를 아주 면밀히 지켜보라.”
“많은 매니저들이 20% 수익이 나면 “연간 성과를 확정짓자, 하이워터마크 찍었으니 바닷가로 가자”라고 합니다. 저는 반대입니다. 조지에게서 많이 배웠죠. 20~30% 올랐을 때는 하우스의 돈으로 플레이하는 겁니다—60~70%까지 노려봐야 할 때죠. 대개 그때는 손이 뜨겁기도 하고요.”