
Insight #116_2025 LLM, 데미스 허사비스, AI와 회사, 의도를 실행하는 회사, 데이터브릭스, 그록(Groq), 메모리, 전력 변화, B2B 스테이블코인, Ribbit Capital, 라포트, 감도(taste)와 확률 그리고 자유
새해가 밝았네요. 모두 새해 복 많이 받으세요!
저는 올해를 그동안 하나씩 쌓아올린 점들을 잘 연결해보는 한 해로 만들어보고 싶습니다. 여러분들은 어떠한 마음가짐으로 한 해를 시작하셨나요?
오늘은 AI, 반도체, 인프라, 핀테크, 금융, 투자, 비즈니스에 대해 다룹니다.
뉴스레터 외에도 텔레그램 및 블로그에서 저의 생각을 접해보실 수 있습니다.
#오리지널
2025년은 그 어느 때보다도 주식 투자에 많은 에너지를 투자했고, 그만큼 배우고 느낀바도 많기에 특별히 투자 회고를 남겨본다.
#AI
안드레 카파시의 2025년 LLM의 회고글.
그가 모델 단의 발전 만큼이나 어플리케이션 단의 발전을 중요하게 관찰하고 있는 것이 느껴진다.
“요약하자면, 2025년은 LLM에 있어 흥미롭고 다소 놀라운 한 해였습니다. LLM은 제가 기대했던 것보다 훨씬 똑똑하면서도 동시에 훨씬 더 멍청한, 새로운 종류의 지능으로 등장하고 있습니다. 어떤 경우든 모델들은 매우 유용하며, 업계가 현재의 역량만으로도 잠재력의 10%조차 실현하지 못했다고 생각합니다. 한편, 시도해 볼 아이디어는 너무나 많고 개념적으로 이 분야는 활짝 열려 있는 기분입니다.”
<검증 가능한 보상을 통한 강화학습 (RLVR)>
“상대적으로 가벼운 단계인 SFT나 RLHF와 달리, RLVR은 조작 불가능한 객관적인 보상 함수를 대상으로 훈련하므로 훨씬 더 긴 최적화가 가능합니다. RLVR을 실행하는 것이 비용 대비 성능(capability/$) 효율이 매우 높다는 사실이 밝혀졌고, 이는 원래 사전 학습에 투입될 예정이었던 컴퓨팅 자원을 흡수해 버렸습니다. 따라서 2025년의 대부분의 성능 진보는 이 새로운 단계의 ‘오버행(overhang)’을 해결하려는 시도들로 정의되었으며, 결과적으로 모델 크기는 비슷하지만 훨씬 더 긴 강화학습(RL) 실행을 보게 되었습니다.”
“또한 이 새로운 단계의 독특한 점은, 추론 경로를 길게 생성하고 ‘생각하는 시간’을 늘림으로써 테스트 시간 연산(test-time compute)의 함수로서 성능을 제어할 수 있는 새로운 노브(그리고 관련된 스케일링 법칙)를 갖게 되었다는 것입니다. OpenAI o1(2024년 말)이 RLVR 모델의 첫 번째 시연이었다면, o3 출시(2025년 초)는 그 차이를 직관적으로 느낄 수 있는 분명한 변곡점이었습니다.”
<유령 vs 동물: 삐죽삐죽한 지능 (Jagged Intelligence)>
“2025년은 저(그리고 업계 전체)가 LLM 지능의 ‘형태’를 더 직관적인 의미로 내면화하기 시작한 해입니다. 우리는 ‘진화하거나 자라나는 동물’을 만들고 있는 것이 아니라, ‘유령을 소환’하고 있는 것입니다. LLM 스택의 모든 것(신경망 구조, 학습 데이터, 학습 알고리즘, 특히 최적화 압력)이 다르기 때문에 지능의 영역에서 매우 다른 개체가 탄생하는 것은 놀라운 일이 아니며, 이를 동물의 관점에서 생각하는 것은 부적절합니다.”
“검증 가능한 도메인이 RLVR을 가능하게 함에 따라, LLM은 해당 도메인 근처에서 성능이 급격히 솟구치며(spike), 전반적으로 재미있을 정도로 삐죽삐죽한(jagged) 성능 특성을 보여줍니다. 모델은 동시에 천재적인 박학다식가이면서도, 데이터 탈취를 위한 탈옥(jailbreak) 수법에 몇 초 만에 속아 넘어가는 인지 장애 수준의 초등학생이기도 합니다. (~) 이와 관련하여 2025년에 저는 벤치마크에 대해 전반적인 무관심과 신뢰 상실을 느꼈습니다.”
<Cursor: 새로운 계층의 LLM 앱>
“올해 Cursor의 눈부신 성장 외에 제가 가장 주목하는 점은, Cursor가 ‘LLM 앱’의 새로운 계층을 설득력 있게 드러냈다는 점입니다. 사람들은 이제 ‘X를 위한 Cursor’를 이야기하기 시작했습니다.”
<Claude Code: 당신의 컴퓨터에 사는 AI>
“Claude Code(CC)는 LLM 에이전트가 어떤 모습인지 보여주는 첫 번째 설득력 있는 사례로 등장했습니다. 이는 도구 사용과 추론을 반복적으로 연결하여 장기적인 문제를 해결하는 형태입니다. 또한 CC는 클라우드가 아닌 당신의 컴퓨터에서 당신의 비공개 환경, 데이터, 컨텍스트와 함께 실행된다는 점에서 주목할 만합니다.”
“OpenAI는 초기 코덱스/에이전트 노력을 ChatGPT에서 오케스트레이션되는 컨테이너 기반의 클라우드 배포에 집중했기 때문에 이 부분을 놓쳤다고 생각합니다. 로컬호스트(localhost)가 정답이었습니다. 클라우드에서 실행되는 에이전트 군단이 ‘AGI의 종착역’처럼 느껴질 수 있지만, 우리는 여전히 지능의 성능이 불규칙한 중간 단계의 세계에 살고 있으며, 에이전트를 개발자의 컴퓨터에서 직접 실행하는 것이 더 합리적입니다.”
<바이브 코딩>
“2025년은 AI가 영어만으로 온갖 인상적인 프로그램을 구축할 수 있는 성능 임계값을 넘은 해입니다. 코드가 존재한다는 사실조차 잊게 만들 정도죠. 재미있게도 제가 트위터에서 ‘바이브 코딩’이라는 용어를 만들었을 때는 이것이 어디까지 갈지 전혀 몰랐습니다. 바이브 코딩을 통해 프로그래밍은 더 이상 고도로 훈련된 전문가들만의 전유물이 아니며, 누구나 할 수 있는 일이 되었습니다.”
<나노 바나나: LLM GUI>
“UI/UX 측면에서 LLM과 ‘채팅’하는 것은 1980년대 컴퓨터 콘솔에 명령어를 입력하는 것과 비슷합니다. 텍스트는 컴퓨터(및 LLM)에게는 가공되지 않은 선호되는 데이터 표현이지만, 인간에게는, 특히 입력 단계에서 선호되는 형식이 아닙니다. 사람들은 실제로 텍스트 읽기를 싫어합니다. 느리고 노력이 필요하기 때문입니다. 대신 사람들은 정보를 시각적이고 공간적으로 소비하는 것을 좋아하며, 이것이 전통적인 컴퓨팅에서 GUI가 발명된 이유입니다. 같은 방식으로, LLM은 우리가 선호하는 형식(이미지, 인포그래픽, 슬라이드, 화이트보드, 애니메이션/비디오, 웹 앱 등)으로 우리에게 말해야 합니다.”
“실제로 누가 LLM GUI를 구축하게 될까요? 이러한 관점에서 ‘나노 바나나’는 그것이 어떤 모습일지에 대한 첫 번째 힌트입니다. 중요한 점은 단순히 이미지 생성 자체에 관한 것이 아니라, 모델 가중치 속에 얽혀 있는 텍스트 생성, 이미지 생성, 세상에 대한 지식이 결합된 능력에서 온다는 것입니다.”
The future of intelligence | Demis Hassabis (Co-founder and CEO of DeepMind)
허사비스가 말하는 AI. 그의 ‘과학자’스러운 면모가 잘 느껴진다.
“Q. 셰인 레그(딥마인드 공동창업자)가 말하길, 노동을 자원과 교환하는 현재의 경제 시스템은 포스트 AGI 사회에서 제대로 작동하지 않을 것이라고 하더군요. 사회가 어떻게 재구성되어야 하는지, 혹은 어떤 방식으로 재구성될 수 있는지에 대한 비전이 있으신가요?”
“A. 요즘 그 부분에 대해 더 많은 시간을 들여 생각하고 있습니다. 셰인 레그가 포스트 AGI 세상의 모습과 우리가 준비해야 할 것들에 대한 연구를 주도하고 있기도 하고요. 하지만 경제학자, 사회과학자, 정부 등 사회 전반이 이 문제에 대해 더 많은 고민을 해야 합니다. 산업 혁명 때 노동 환경과 주 5일제 등이 농경 사회와는 완전히 다르게 바뀌었던 것처럼, 이번에도 그 정도 수준의 변화가 일어날 것입니다. 놀라운 일이 아니죠.”
“이 변화를 돕고 혜택이 널리 분배되도록 하기 위해 새로운 경제 시스템이나 모델이 필요하다는 사실에 놀라지 않을 것입니다. 보편적 기본 소득(UBI) 같은 정책들이 해결책의 일부가 될 수도 있겠죠. 하지만 그것이 완전한 정답이라고는 생각하지 않습니다. 그것은 현재 우리가 모델링할 수 있는 수준의 ‘추가 기능(Add-on)’일 뿐입니다. 하지만 Credits 같은 것으로 자신이 원하는 것에 투표하는 ‘직접 민주주의’ 시스템 같은 훨씬 더 나은 시스템이 등장할 수도 있습니다. 이미 지역 커뮤니티 수준에서 이루어지고 있는 일이죠. “여기 예산이 있습니다. 놀이터를 원하나요, 테니스 코트를 원하나요, 아니면 학교 교실 증축을 원하나요?”라고 묻고 커뮤니티가 투표하게 하는 겁니다. 나아가 결과를 측정하고, 결과적으로 좋은 반응을 얻은 제안에 투표한 사람들에게 다음 투표에서 비례적으로 더 많은 영향력을 주는 식의 아이디어도 있습니다. 제 경제학자 친구들이 브레인스토밍하는 흥미로운 아이디어들이 많은데, 이런 분야에 더 많은 연구가 이루어지길 바랍니다.”
“철학적인 측면도 있습니다. 직업의 형태가 바뀌고 핵융합 에너지가 해결되어 에너지가 거의 무료가 되는 ‘포스트 희소성(Post-scarcity)’ 시대가 왔다고 해봅시다. 그러면 돈은 어떻게 될까요? 모두가 더 잘살게 되겠지만, ‘목적(Purpose)’은 어떻게 될까요? 많은 사람들이 자신의 직업과 가족을 부양하는 것에서 삶의 목적을 찾는데, 그것은 매우 숭고한 목적입니다. 만약 그것이 바뀐다면 경제적인 문제를 넘어 철학적인 질문으로 이어집니다.”
“Q.인간이 할 수 있는 일 중에 기계가 절대 할 수 없는 일이 있다고 생각하시나요?”
“A. 그것이 가장 큰 질문입니다. 제 인생에서 가장 좋아하는 주제 중 하나인 튜링 머신과 관련된 질문이기도 하죠. 저는 항상 AGI를 구축해 마음의 시뮬레이션으로 사용하고 이를 실제 마음과 비교해 본다면 그 차이점이 무엇인지, 인간의 마음 속에 여전히 특별하게 남아 있는 것이 무엇인지 알 수 있을 것이라고 느껴왔습니다. 그것은 창의성일 수도, 감정일 수도, 꿈일 수도 있습니다.”
“의식에 대해서도 많은 가설이 있고, 무엇이 계산 가능한지 아닌지에 대한 가설도 많습니다. 이것은 튜링 머신의 한계가 무엇인가 하는 질문으로 돌아갑니다. 그것이 제 인생의 핵심 질문입니다. 제가 튜링과 튜링 머신에 대해 알게 된 이후로 쭉 말이죠. 그것은 저의 핵심적인 열정입니다. 우리가 해온 모든 일은 단백질 폴딩을 포함해 튜링 머신이 할 수 있는 것의 한계를 끝까지 밀어붙이는 일이었습니다.”
“그 한계가 무엇인지 저도 잘 모르겠습니다. 어쩌면 한계란 없을 수도 있죠. 물론 제 양자 컴퓨팅 친구들은 한계가 존재하며 양자 시스템을 모델링하려면 양자 컴퓨터가 필요하다고 말할 것입니다. 하지만 저는 정말로 잘 모르겠습니다. 양자 컴퓨팅 동료들과도 토론해 봤는데, 고전적인 시뮬레이션을 만들기 위해 양자 시스템의 데이터가 필요할 수도 있습니다.”
“다시 마음의 문제로 돌아가면, 그것이 모두 고전적인 계산(Classical computation)인지, 아니면 다른 무언가가 일어나고 있는지의 문제입니다. 로저 펜로즈(Roger Penrose)는 뇌 속에 양자 효과가 있다고 믿습니다. 만약 그렇고 그것이 의식의 정체라면, 기계는—적어도 고전적인 기계는—절대 그것을 가질 수 없을 것입니다. 양자 컴퓨터가 나올 때까지 기다려야겠죠. 하지만 그렇지 않다면 한계는 없을 수도 있습니다.”
“우주의 모든 것이 계산적으로 처리 가능(Computationally tractable)할 수도 있습니다. 만약 올바른 방식으로 바라본다면 추론하는 기계가 우주의 모든 것을 모델링할 수 있을지도 모릅니다. 현재로서는 저도 그렇게 추측하고 있으며, 물리학이 반대 증거를 보여줄 때까지는 그 가설을 바탕으로 연구하고 있습니다. 즉, 이러한 계산적 틀 안에서 할 수 없는 일은 없다는 것이죠. 지금까지 우주에서 계산 불가능한 것은 아무도 찾아내지 못했습니다. 지금까지는 말이죠.”
“고전적인 컴퓨터가 할 수 있는 일에 대해 기존의 복잡성 이론가들이 가진 P=NP의 시각을 훨씬 뛰어넘을 수 있다는 것을 우리는 이미 단백질 폴딩이나 바둑 등을 통해 보여주었습니다. 그래서 그 한계가 어디인지 아무도 모른다고 생각합니다. 딥마인드와 구글에서 제가 하려는 일은 바로 그 한계를 찾는 것입니다.”
“결국 이에 대한 제 견해는—제가 AI를 사랑하는 이유이기도 한데—마음의 구성물(Construct of the mind)이라는 철학에 기반합니다. 방금 말씀하신 그 모든 것들은 우리의 감각 기관을 통해 들어오고 다르게 느껴집니다. 조명의 따뜻함, 테이블의 감촉 등이 말이죠. 하지만 결국 그것들은 모두 ‘정보’입니다. 그리고 우리는 ‘정보 처리 시스템’입니다. 생물학이 바로 그것이라고 생각합니다.”
“우리가 Isomorphic systems을 통해 하려는 작업도 그것입니다. 생물학을 정보 처리 시스템으로 생각함으로써 결국 모든 질병을 치료하게 될 것이라고 믿습니다. 저는 제 얼마 안 되는 여유 시간에도 정보가 에너지나 물질이 아닌 우주의 가장 근본적인 단위라는 물리학 이론들을 고민하고 있습니다.”
“Q. 다음 10년을 생각할 때, 개인적으로 가장 우려되는 순간이 있나요?”
“A. 지금의 시스템들은 제가 ‘수동적인 시스템’이라고 부르는 단계에 있습니다. 사용자가 질문이나 과제를 던져 에너지를 투입하면 시스템이 요약이나 답변을 제공하죠. 인간이 주도하고 인간의 에너지와 아이디어가 들어가는 방식입니다. 다음 단계는 ‘에이전트 기반 시스템(Agent-based systems)’입니다. 지금도 시작되고 있지만 아직은 원시적이죠. 향후 몇 년 안에 정말 인상적이고 신뢰할 수 있는 에이전트들이 나오기 시작할 것입니다. 어시스턴트로서 믿을 수 없을 정도로 유용하고 유능하겠지만, 동시에 더 자율적일 것입니다.”
“따라서 그런 유형의 시스템이 가져올 위험도 커집니다. 저는 2~3년 뒤에 그런 시스템들이 무엇을 할 수 있게 될지 꽤 걱정됩니다. 우리는 수백만 개의 에이전트들이 인터넷을 돌아다니는 세상을 대비해 사이버 방어 기술을 연구하고 있습니다.”
Elon Musk on AGI Timeline, US vs China, Job Markets, Clean Energy & Humanoid Robots | 220
일론 머스크: 특이점은 이미 시작됐다 - Jian (한글 요약)
많은 사람들이 선형적인 미래를 예측할 때, 머스크는 직접 미래를 만들다보니 지수적인 미래가 그려지는 것이겠지.
그의 말이 다 맞진 않겠지만 (특히 타임라인은 꽤나 다르겠지만) 전반적인 방향성은 언제나처럼 많이 맞을 것 같다.
“Share what you truly care about. Family, Creativity, space exploration, whatever lights you up. Then picture how tech could weave right into that, making it bigger, brighter.”
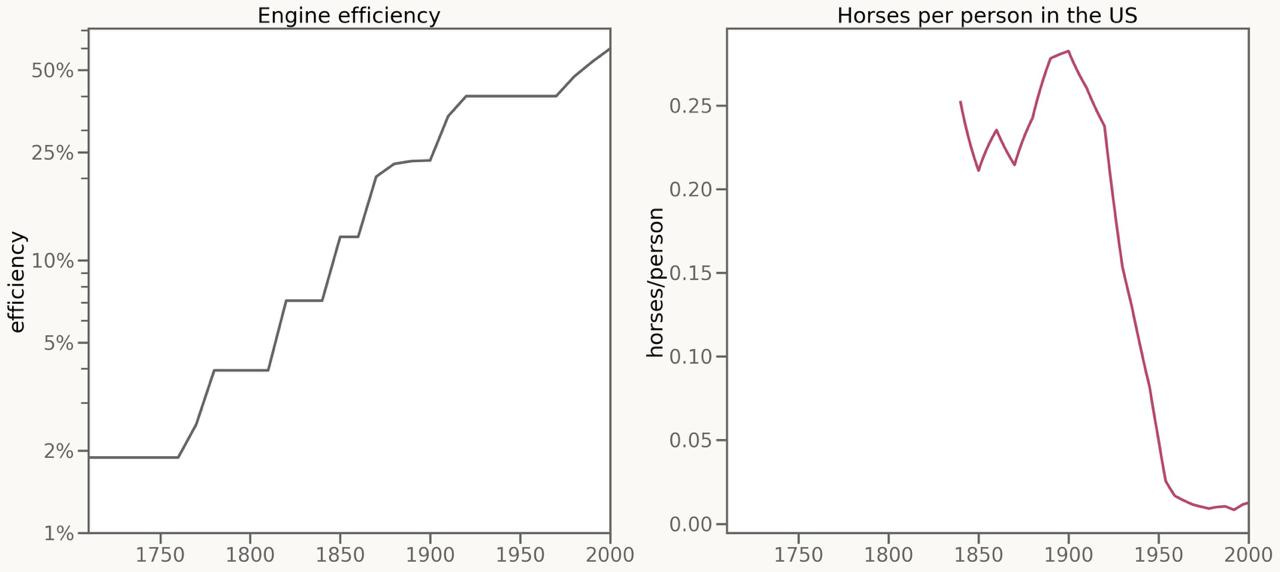
일리야는 최근 인터뷰에서 “모델들이 여러 평가(evals)에서 아주 잘하고 있죠. 그런데 경제적 영향은 그에 한참 뒤처져 있어요. 이 둘을 어떻게 조화시켜 이해해야 할지 매우 어렵습니다.”라고 말하였다.
관련해서 최근 트위터에서 이런 그림을 보았다. 엔진 효율성은 꾸준히 증가했지만, 실제 현실에서 말이 자동차로 전환된건 급격하게 일어났다는걸 보여주고 있다.
이게 왜 그런걸까? 고민해보았지만 명확한 답은 떠오르지 않았는데, 일단 ‘왜’에 앞서서 AI 또한 이럴 수 있다는걸 열어두어야 할 것 같다.
무엇이 임계점을 넘기게 만들어줄진 모르겠으나, 임계점을 넘는 순간 AI가 급격하게 사회에 영향을 미칠 수 있겠단 소리.
Steam, Steel, and Infinite Minds
노션을 만든 이반 자오가 말하는 AI. 10000% 동의한다. AI는 제품 만큼이나 ‘회사’를 크게 바꿔놓을 것이다.
“철강은 도금 시대(Gilded Age)를 일구어냈고, 반도체는 디지털 시대의 전원을 켰습니다. 이제 AI가 ‘무한한 지능(Infinite Minds)’이 되어 우리 곁에 왔습니다. 역사가 우리에게 가르쳐 주는 것이 있다면, 소재를 지배하는 자가 그 시대를 정의한다는 사실입니다.”
“저의 공동 창업자인 사이먼은 소위 ‘10x 개발자’였지만, 요즘은 코드를 직접 쓰는 일이 거의 없습니다. 그의 책상을 지나가다 보면 그가 3~4개의 AI 코딩 에이전트를 동시에 지휘하는 모습을 볼 수 있습니다. 이 에이전트들은 단순히 타자가 빠른 것이 아니라 스스로 사고하며, 덕분에 사이먼은 ‘30~40배수 엔지니어’가 되었습니다. 그는 점심시간이나 잠들기 전에 업무를 대기열에 걸어두고, 자신이 자리를 비운 사이에도 일을 시킵니다. 그는 ‘무한한 지능의 관리자’가 된 것입니다.”
“AI 에이전트 덕분에 사이먼 같은 사람들은 이제 자전거를 타는 단계에서 자동차를 운전하는 단계로 올라섰습니다. 다른 지식 노동자들은 언제쯤 이 ‘자동차’를 갖게 될까요? 그러기 위해선 두 가지 문제가 해결되어야 합니다.”
“첫째, 맥락의 파편화(Context Fragmentation)입니다. 코딩의 경우 도구와 맥락이 IDE(통합 개발 환경), 레포지토리, 터미널 등 한곳에 모여 있습니다. 하지만 일반적인 지식 노동은 수십 개의 도구에 흩어져 있습니다. 제품 기획안을 작성하는 AI 에이전트를 상상해 보세요. 슬랙 메시지, 전략 문서, 대시보드의 지난 분기 지표, 그리고 누군가의 머릿속에만 있는 암묵지까지 끌어와야 합니다. 오늘날 인간은 복사-붙여넣기와 탭 전환을 반복하며 이 파편들을 이어 붙이는 ‘풀’ 역할을 하고 있습니다. 이 맥락들이 통합되기 전까지 에이전트는 좁은 범위의 작업에만 머물 것입니다.”
“둘째, 검증 가능성(Verifiability)입니다. 코드는 테스트와 오류를 통해 즉시 확인할 수 있는 마법 같은 속성이 있습니다. 모델 개발자들은 이를 이용해 강화 학습으로 AI의 코딩 능력을 향상시킵니다. 하지만 프로젝트가 잘 관리되고 있는지, 전략 기획서가 훌륭한지 어떻게 검증할 수 있을까요? 일반 지식 노동을 위해 모델을 개선할 방법은 아직 찾지 못했습니다. 그래서 여전히 인간이 ‘루프 안에(Human-in-the-loop)’ 머물며 감독하고 가이드해야 합니다.”
“올해의 코딩 에이전트들은 우리에게 ‘인간의 개입’이 항상 바람직한 것은 아님을 가르쳐 주었습니다. 그것은 마치 공장 라인의 모든 볼트를 사람이 직접 점검하거나, 길을 비우기 위해 자동차 앞에서 걷는 것과 같습니다. 우리는 인간이 루프 안에서 직접 뛰는 게 아니라, 지렛대 효과를 발휘할 수 있는 지점에서 루프를 감독하기를 원합니다. 맥락이 통합되고 업무 검증이 가능해지면, 수십억 명의 노동자들은 페달을 밟는 단계에서 운전으로, 그리고 자율주행의 단계로 나아갈 것입니다.”
“회사라는 개념은 비교적 최근의 발명품입니다. 회사는 규모가 커질수록 효율이 떨어지며 한계에 다다릅니다. 두 가지 역사적 비유는 새로운 ‘기적의 소재’를 통해 미래의 조직이 어떻게 달라질 수 있는지 보여줍니다.”
“첫 번째는 철강입니다. 철강이 등장하기 전 19세기 건물들은 6~7층이 한계였습니다. 철은 강했지만 부서지기 쉽고 무거웠습니다. 층을 더 올리면 구조물이 자체 무게를 견디지 못하고 무너졌습니다. 철강은 모든 것을 바꿨습니다. 강하면서도 유연했습니다. 프레임은 가벼워지고 벽은 얇아졌으며, 건물은 수십 층 높이로 솟아올랐습니다. 완전히 새로운 종류의 건축물이 가능해진 것입니다.”
“두 번째는 증기기관입니다. 산업 혁명 초기, 방직 공장들은 수로 옆에 위치해 수차(Waterwheel)의 동력을 이용했습니다. 증기기관이 처음 등장했을 때, 공장주들은 단순히 수차를 증기기관으로 교체했을 뿐 나머지는 그대로 두었습니다. 생산성 향상은 미미했습니다. 진정한 돌파구는 공장주들이 물로부터 완전히 독립할 수 있다는 사실을 깨달았을 때 찾아왔습니다. 그들은 노동자, 항구, 원자재와 더 가까운 곳에 더 큰 공장을 지었습니다. 그리고 증기기관을 중심으로 공장을 완전히 재설계했습니다. 생산성은 폭발했고 제2차 산업 혁명이 본격적으로 시작되었습니다.”
“제가 운영하는 노션에서는 이미 실험을 진행 중입니다. 1,000명의 직원과 함께 700개 이상의 에이전트가 반복적인 업무를 처리하고 있습니다. 에이전트들이 회의록을 작성하고 질문에 답하며 조직 내의 지식을 합성합니다. IT 요청을 처리하고 고객 피드백을 기록하며, 신입 사원의 복지 혜택 온보딩을 돕습니다. 사람들이 복사-붙여넣기를 하지 않도록 주간 상태 보고서를 작성하기도 합니다. 이것은 시작에 불과합니다. 진정한 이득은 오직 우리의 상상력과 타성에 의해서만 제한될 뿐입니다.”
“철강과 증기는 건물과 공장만 바꾼 것이 아닙니다. 도시를 바꿨습니다. 몇백 년 전까지 도시는 ‘인간 규모’였습니다. 피렌체는 걸어서 40분이면 가로지를 수 있었습니다. 삶의 리듬은 사람이 얼마나 멀리 걸을 수 있는지, 목소리가 얼마나 멀리 들리는지에 의해 결정되었습니다.”
“그러다 철골 구조가 마천루를 가능하게 했고, 증기기관이 도심과 외곽을 잇는 철도를 움직였습니다. 엘리베이터, 지하철, 고속도로가 그 뒤를 이었습니다. 도시는 규모와 밀도 면에서 폭발했습니다. 도쿄, 충칭, 댈러스 같은 곳들입니다.”
“이 도시들은 단순히 피렌체의 확장판이 아닙니다. 완전히 다른 삶의 방식입니다. 메가시티는 혼란스럽고 익명성이 강하며 길을 찾기도 어렵습니다. 그런 ‘가독성의 저하’는 규모를 확장하기 위해 지불해야 하는 대가입니다. 하지만 그 대가로 메가시티는 더 많은 기회와 자유를 제공합니다. 인간 규모의 르네상스 도시에서는 불가능했던 조합으로 더 많은 사람이 더 많은 일을 해냅니다.”
“지식 경제도 이와 같은 변화를 겪기 직전이라고 생각합니다. 현재 지식 노동은 미국 GDP의 거의 절반을 차지합니다. 그러나 대부분은 여전히 수십 명 규모의 팀, 회의와 이메일에 맞춘 업무 속도 등 ‘인간 규모’로 작동합니다. 우리는 돌과 나무로 ‘피렌체’를 짓고 있었던 셈입니다.”
“AI 에이전트가 대규모로 도입되면 우리는 도쿄를 건설하게 될 것입니다. 수만 명의 에이전트와 인간이 공존하는 조직, 깨어날 누군가를 기다리지 않고 시차를 초월해 24시간 돌아가는 업무 흐름, 적절한 수준의 인간 개입으로 합성된 의사결정들이 나타날 것입니다.”
“그것은 생경한 느낌일 것입니다. 더 빠르고 더 큰 지렛대를 갖게 되겠지만, 처음에는 더 혼란스러울 것입니다. 주간 회의, 분기별 계획, 연례 성과 평가 같은 리듬은 더 이상 의미가 없어질지 모릅니다. 새로운 리듬이 등장할 것입니다. 우리는 명료함을 일부 잃는 대신, 규모와 속도를 얻게 될 것입니다.”
“모든 ‘기적의 소재’는 사람들이 백미러를 통해 세상을 보는 것을 멈추고 새로운 세상을 상상할 것을 요구했습니다. 카네기는 철강을 보며 도시의 스카이라인을 보았습니다. 랭커셔의 공장주들은 증기기관을 보며 강물로부터 자유로워진 공장을 보았습니다.”
“우리는 여전히 AI의 ‘수차 단계’에 있습니다. 인간을 위해 설계된 업무 흐름에 챗봇을 덧붙이고 있을 뿐입니다. 우리는 AI에게 단순히 우리의 Copilot이 되어 달라고 요구하는 것을 멈춰야 합니다. 인간 조직이 철강으로 보강되고, 잡무가 잠들지 않는 지능에 위임되었을 때 지식 노동의 모습이 어떨지 상상해야 합니다.”
“철강. 증기. 그리고 무한한 지능. 다음 시대의 스카이라인은 그곳에 있으며, 우리가 그것을 세우길 기다리고 있습니다.”
[Two Cents #85] “Flights of Thought” on Consumer + AI — Part 11: 소비자 행태 변화 — 3. Interface에서 Intent로
AI 어플리케이션 관점에서 하나의 가설: “앱을 만드는 회사”가 아니라 “의도를 실행하는 회사”에게 기회가 있다는 주장.
나는 ‘의도(Intent)’파악이 중요해진다는 주장은 동의하는데, 약간 생각이 다른 부분은 결국 이러한 의도 파악 부분까지도 UIUX로 통합적으로 녹여내는 자가 최종 승리하지 않을까 하는 생각을 가지고 있다.
“AI가 “생성”을 넘어 “실행”까지 담당하기 시작하면, 인터넷/모바일 생태계의 기본 단위가 앱(App)에서 ‘의도(Intent)’로 바뀐다. 사용자는 더 이상 기능을 찾아 앱을 설치하고 학습하는 대신, 원하는 목표를 말하고(또는 암묵적으로 드러내고) 시스템이 이를 분해·조합해 처리하는 경험이 기반이 될 것이다. 이때 가치가 쌓이는 지점은 UI의 미세한 차이나 기능의 개수보다는, 누가 사용자의 ‘의도’를 정확히 파악아고, 이를 달성하기 위하여 “누구에게 어떻게 위임하고”, “최종 결과물에 대한 결정은 누가 어떻게 하느가”로 이동한다.”
“그리고, 이 과정을 주도하는 것은, 인간 (소비자)가 아니라 multi-level agent swarm가 될 것이고, 그리고 이들 agent에게 실제 서비스를 제공하는 공급자가 ‘headless’ 형태 혹은 agent, micro-services 등의 형태로 존재할 것으로 본다.”
“이 변화는 자연스럽게 시장을 양극화한다. 한쪽에서는 항공/GDS처럼 표준화된 공급을 묶어 제공하는 소수의 headless supplier/aggregator가 더 중요해지고, 다른 한쪽에서는 아주 작은 기능 단위의 micro capability(스킬/미니앱/툴)가 폭발적으로 증가할 것이다. 과거에는 “큰 앱 안에 많은 기능”이 경쟁력의 핵심이었다면, 앞으로는 “워크플로우가 여러 capability를 필요에 따라 호출”하는 구조가 된다. 결과적으로 전통적인 앱 번들은 해체되고, 사용자 경험은 “앱을 넘나드는 전환 비용”이 아니라 “의도→실행”의 end-to-end 품질로 재정의된다.”
Disney and OpenAI, Totems in an AI World, Google Versus the World - Stratechery
AI로 인해 초개인화가 발전한다고 대중성(=IP)의 중요함이 사라지는건 아니다. 오히려 강화된다고 보는게 합리적이지.
나는 그래서 AI 시대에서는 더더욱 감도가 높아야 한다고 생각한다.
“저는 AI가 지배하는 세상에서 Stratechery와 같은 콘텐츠가 오히려 더 가치 있어질 것이라고 믿습니다. 설령 Gemini나 ChatGPT가 저보다 분석을 더 잘하게 되더라도 말이죠. 그 이유는 LLM 기반 AI가 ‘콘텐츠의 개인화’를 극한으로 밀어붙이기 때문입니다. AI 콘텐츠는 각 사용자에게 개별적으로 생성되기에 사회적 흔적을 남기기 어렵습니다.”
“반면, 이 글(Stratechery Update)은 수만 명의 사람들이 모두 똑같은 내용을 읽고 있습니다. 이것은 관점에 따라 단점일 수 있지만(개인화되지 않았으므로), 모두가 같은 내용을 공유하기 때문에 대화와 커뮤니티를 위한 유용한 ‘토템(구심점)’이 됩니다. 동료와 대화할 때 “그 글 봤어?”라고 말하며 공통의 출발점을 가질 수 있는 것이죠. AI는 이런 경험을 제공하지 못합니다.”
“디즈니의 브랜드 역시 AI 세상에서 더 가치 있는 토템이 될 것입니다. Sora가 처음 출시되었을 때 가장 흥미로웠던 것은 자신의 모습을 영상에 넣는 ‘카메오’ 기능이었습니다. 하지만 카메오는 아는 사람들 사이에서만 의미가 있습니다. 보편적인 토템이 필요합니다.”
“모든 사람은 미키 마우스가 누구인지 압니다. 따라서 미키 마우스를 활용한 기발한 AI 영상은 이름 모를 동물이나 모르는 사람이 나오는 영상보다 기본적으로 더 흥미롭습니다. 설령 그것이 ‘AI 슬롭(Slop, 저품질 콘텐츠)’이라 할지라도, 디즈니라는 토템이 있다면 널리 퍼질 가능성이 생깁니다. 그리고 만약 그렇게 된다면, 디즈니는 그 과정에서 수익을 낼 수 있는 체계를 갖춰둔 셈입니다.”
2025년을 보내며, 놓아주기 싫은 한 해 - Seung
“저는 한때 AI가 만들어 낼 사회상에 대해 부정적인 인식을 가졌습니다. 그러나 비교적 최근 들어 이러한 생각은 변했습니다. 산업을 이해하고, 공부할수록, 또 시간이 지나 AI의 전개를 목도할수록 크게 2가지 생각이 바뀌게 되었습니다. 1) AI는 인류 역사상 가장 민주적인 도구다 2) AI에는 물리법칙 상의 제약이 존재한다.”
“저는 제 스스로의 능력치들을 계량화해서 이해하고 있는 편인데, 가령 제 능력 중에 가장 중요한 것은 정보 해석 능력과 독해력입니다. 저는 최상의 컨디션화에서, 집중력이 고조되면 1시간에 100p 정도의 라이트 한 텍스트를 읽을 수 있습니다. 다소 집중이 필요한 글감은 60p를 소화합니다. 반면 기술적인 내용이나 고도의 집중이 필요한 내용은 한 시간에 약 15~20p 정도 읽을 수 있습니다. 대상이 영어라면 속도는 반토막이 납니다. 그런데 AI가 들어서면서, 전반적인 정보 섭취 능력이 3배 정도 개선됐습니다.”
“결국 뭘 말하고 싶냐면, 현재는 [도메인 지식 X AI]의 조합이 가장 폭발적인 시너지를 일으킬 수 있는 구간이라는 점입니다. 하지만 이 우위는 항구적이지 않을 것입니다. 어느 시점에는 도메인 지식 없이도 AI가 홀로 오롯이 작동하는 구간이 올 것이기 때문입니다.”
“결국 특정 영역에 메어있는 개인들은 현재의 Sweet Spot에서 AI를 활용하여 자신의 영역을 극도로 레버리지 해야 합니다. 그렇지 못한 이들과의 초격차를 벌리고, 유무형의 영향력을 획득해야 AI Alone 시대에서의 생존이 가능하기 때문입니다. 여기서의 생존은 생물학적인 생존을 의미하지는 않습니다.”
“내년을 생각하면, Post Sweet Spot 을 대비하기 위한 체력을 키우는 원년으로 삼고 싶습니다. 주식을 통한 자산증식은 끊임없이 이뤄지는 과업이나, 어느 시점부터 적극적인 알파는 얻기가 힘들어질 것이라 생각합니다. 특히 위에서 언급했듯, 재화가 흔해지는 세상에서는 ‘무엇을 하는’ 인간인지가 더욱 중요해집니다. 역설적으로 자아정체성이 의미 있는 시대가 되는 것입니다.”
데이터브릭스의 밸류는 일년만에 2배 상승했군 ($134b 밸류로 $4b 투자 유치, 참고로 지난 라운드는 $62b). 성장 또한 YoY 55% 달성하며 ARR $4.8b 기록.
스노우플레이크를 상대로 승기를 잡은걸 넘어, 이제 스노우플레이크보다 80% 가량 높은 기업가치를 지닌 회사가 되었다.
“바이브 코딩과 생성형 AI의 동시적인 성장은 기업에서 데이터 기반 지능형 애플리케이션 개발을 가속화하고 있습니다. Databricks는 이번 투자를 통해 고객이 자체 데이터를 기반으로 AI 앱과 에이전트를 구축할 수 있도록 지원할 예정이며, 이를 위해 Lakebase를 기록 시스템으로, Databricks 앱을 사용자 경험 레이어로, Agent Bricks를 다중 에이전트 시스템 구동 도구로 활용할 계획입니다.”
아래는 작년 12월에 데이터브릭스 투자유치를 보고 적어둔 메모인데, 여전히 비슷한 생각을 가지고 있다.
“결국 AI의 키는 데이터를 얼마나 잘 관리하느냐에 달려있는데, 팔란티어는 데이터 관리 능력이 비교적 없는 레거시 기업을 상대로 컨설팅+소프트웨어를 제공하면서 이들을 사로잡는데 성공했다면, 데이터브릭스는 그래도 데이터를 어느정도 관리해오던 기업들에게 데이터를 AI와 결합하여 더욱 잘 활용할 수 있도록 도구를 제공하는 회사라고 볼 수 있겠습니다. 이 생각이 맞다면 팔란티어와 더불어서 오랜 기간동안 청바지 역할을 하게 될 중요한 회사가 될 수 있다고 생각합니다.”
Manus Joins Meta: Accelerating AI Innovation for Businesses
메타는 마누스(Manus)를 인수하며 에이전트 역량을 강화.
#반도체
Nvidia v. Google, Scaling Laws, and the Economics of AI - Colossus
AI의 경쟁력을 미리 예측하기 위해 반도체(컴퓨팅) 레이어를 알아야만 하는 이유:
네, 제미나이 3는 매우 중요했습니다. 왜냐하면 사전 학습(pre-training)에 대한 스케일링 법칙이 건재하다는 것을 보여주었기 때문입니다. 그들은 명확하게 그렇게 말했습니다. 이게 왜 중요하냐면, 지구상에 누구도 스케일링 법칙이 ‘왜’ 또는 ‘어떻게’ 작동하는지 정확히 아는 사람이 없기 때문입니다. 사실 이건 법칙이라기보다 경험적 관찰에 가깝습니다. 우리가 매우 정밀하게 측정해왔고 오랫동안 유지되어 온 경험적 관찰이죠.
우리가 이렇게 발전할 수 있었던 이유, 오픈AI의 첫 추론(reasoning) 모델이 나왔을 때 3개월 만에 8%에서 95%로 뛴 이유는, 두 가지 새로운 스케일링 법칙 때문입니다. 바로 검증된 보상을 통한 강화 학습과 테스트 타임 컴퓨팅입니다. 24년 10월부터 오늘까지의 모든 엄청난 진보는 전적으로 이 두 가지 새로운 법칙 덕분입니다.
제미나이 3는 호퍼 이후 사전 학습 스케일링 법칙에 대한 첫 번째 테스트였고, 그게 유지되었습니다. 이게 훌륭한 이유는 모든 스케일링 법칙이 곱셈 효과(multiplicative)를 내기 때문입니다. 이제 우리는 훨씬 더 좋은 기본 모델에 이 두 가지 새로운 강화 학습(검증된 보상과 테스트 타임 컴퓨팅)을 적용하게 될 것입니다.
만약 ‘추론(Reasoning)’ 기술이 등장하지 않았다면, 2024년 중반부터 제미나이 3가 나올 때까지 AI 진보는 전혀 없었을 겁니다. 모든 게 정체되었겠죠.
구글은 2024년에 TPU v6, 2025년에 TPU v7을 내놓았습니다. 반도체 시간으로 보면 호퍼(Hopper)는 2차 대전 시대의 비행기 같습니다. 당시엔 최고의 비행기였죠, 멀린 엔진을 단 P-51 머스탱처럼요. 하지만 반도체 시간으로 2년 뒤면 그건 F-4 팬텀이 됩니다. 블랙웰이 너무 복잡하고 램프업하기 힘들었기 때문에, 구글은 제미나이 3를 24, 25년형 TPU(F-4 팬텀급)로 훈련시켰습니다. 블랙웰은 F-35 같은 거죠. 그걸 가동하는 데 정말 오랜 시간이 걸렸습니다.
그래서 저는 구글이 사전 학습 관점에서 현재 일시적인 우위를 점하고 있다고 봅니다. 또한 그들이 토큰당 생산 비용이 가장 낮다는 점도 중요합니다. 기술 투자자로서 제 경력상 ‘저비용 생산자(low-cost producer)’가 되는 게 중요했던 적은 이번 AI가 처음입니다.
애플이나 마이크로소프트, 엔비디아가 수조 달러 가치를 지닌 건 그들이 폰이나 소프트웨어, 칩을 싸게 만들어서가 아닙니다. 그건 중요하지 않았습니다. 하지만 구글이 저비용 생산자로서 해온 일은 AI 생태계의 ‘경제적 산소’를 빨아들이는 것이었습니다. 이는 그들에게 매우 합리적인 전략입니다. 경쟁자들을 힘들게 만드는 거죠.
이제 무슨 일이 일어날까요? 여기엔 심오한 함의가 있습니다. 첫째, 2026년 초에 블랙웰로 훈련된 첫 모델들을 보게 될 겁니다. 저는 첫 블랙웰 모델이 xAI에서 나올 거라고 생각합니다. 젠슨에 따르면 일론 만큼 데이터 센터를 빨리 짓는 사람이 없으니까요.
블랙웰이 있어도 호퍼 수준의 성능을 내려면 6~9개월이 걸립니다. 호퍼는 이미 최적화되어 있고, 소프트웨어도 완벽하며, 엔지니어들이 모든 특성을 다 알고 있거든요. 반면 블랙웰은 젠슨이나 엔비디아 입장에서는 최대한 빨리 한 데이터 센터에 많이 깔아서 버그를 잡아야 합니다. xAI가 엔비디아를 위해 해주는 역할이 바로 이겁니다. 가장 빨리 짓고 가장 빨리 대규모로 배포해서 버그를 잡는 걸 돕는 거죠.
그래서 xAI가 첫 블랙웰 모델을 가질 겁니다. 사전 학습 스케일링 법칙이 유효하다는 걸 알기에, 이 블랙웰 모델들은 엄청날 겁니다. 블랙웰은 F-35 대 F-4 팬텀 정도는 아니더라도, F-35 대 라팔(Rafale) 정도의 격차는 될 겁니다. 훨씬 더 좋은 칩이죠.
그다음 더 중요한 일이 일어납니다. GB200(블랙웰) 랙을 가동하기가 정말 힘들었지만, GB300은 훌륭한 칩입니다. GB200 랙에 그대로 끼울 수 있습니다(drop-in compatible). 이제 GB200을 교체할 필요가 없죠. 따라서 GB300을 사용하는 회사들이 토큰의 저비용 생산자가 될 겁니다. 특히 수직 통합된 회사라면요.
이건 구글의 전략적 계산을 바꿔야 할 심오한 의미가 있습니다. 만약 당신이 결정적인 비용 우위를 가지고 있고 검색 등 다른 사업이 있다면, AI를 마이너스 30% 마진으로 돌리는 게 합리적입니다. 경쟁자들의 자금 조달을 어렵게 만드는 거죠. 하지만 구글이 더 이상 저비용 생산자가 아니게 되면 그 계산이 바뀝니다. 블랙웰 모델이 훈련되고 나면 Inference용으로 전환될 겁니다.
구글이 고비용 생산자로서 마이너스 30% 마진을 감당하기 고통스러워져서 행동을 바꾼다면, 이는 AI 경제에 큰 영향을 미칠 겁니다. 그리고 루빈(Rubin, 엔비디아의 다음 칩)이 나오면 격차는 더 벌어질 겁니다. (TPU 대비해서요?) 네, TPU와 다른 모든 ASIC(주문형 반도체) 대비해서요.
”We’re Ahead of Where I Thought We’d Be” — Gemini 3 & the Future of AI
제미나이의 사전훈련 담당자 인터뷰.
구글은 전통적으로 컴퓨팅 엔지니어링에 강점이 있는 회사였고, 이 역량이 또 한번 발휘되면서 AI 선두에 자리하게 되었다.
“점점 더 중요해지고 있는 한 가지는 연구를 수행할 수 있으면서도 시스템적인 측면을 인식하는 것입니다. 우리는 이제 상당히 복잡한 시스템들을 구축하고 있습니다. 따라서 TPU에서 연구에 이르기까지 스택이 어떻게 작동하는지 끝까지 이해할 수 있는 능력은 일종의 슈퍼파워입니다. 왜냐하면 그렇게 함으로써 다른 사람들이 반드시 볼 수 없는 서로 다른 레이어 사이의 간극을 찾을 수 있을 뿐만 아니라, 자신의 연구 아이디어가 TPU 스택에 이르기까지 어떤 영향을 미칠지 추론할 수 있기 때문입니다. 그런 일을 잘할 수 있는 사람들은 일반적으로 많은 영향력을 갖는다고 생각합니다. 전문화라는 측면에서 보자면 순수한 모델 아키텍처 연구뿐만 아니라 모델 연구의 이러한 연구 엔지니어링 및 시스템 측면에 대해 생각하는 것입니다.”
추가로) 올해 어떤 발전이 등장할지에 대한 힌트가 나와있네. 내 생각엔 긴 문맥을 잘 다루게 되면 AI가 지금보다 n배는 유용해질 것 같은데.
“제미나이 1.5에서 모델의 긴 문맥(long context) 능력에서 정말 좋은 도약이 있었다고 생각하며 그것이 정말 많은 것을 가능하게 한다고 봅니다. 오늘날 코드베이스를 가지고 작업을 많이 해서 문맥 길이가 정말 길어지는 상황에서 모델과 에이전트가 이 작업을 수행할 수 있는 능력입니다. 26년쯤에는 긴 문맥을 더 효율적으로 만드는 것뿐만 아니라 모델 자체의 문맥 길이를 더 확장하는 측면에서 더 많은 혁신이 있을 것이라고 생각합니다. 따라서 능력 측면에서 사전 학습이 구체적으로 제공할 수 있는 것이 많고 매우 흥미롭습니다. 이와 관련하여 어텐션(attention) 측면에서도 최근에 정말 흥미로운 발견들을 했는데 그것이 향후 몇 달 동안 우리가 수행할 많은 연구의 형태를 결정할 것이라고 생각하며 개인적으로 매우 기대가 큽니다.”
엔비디아가 그록(Groq)을 약 $20b 규모로 사실상의 인수를 진행한다 (정확히는 기술 라이센싱 및 경영진 영입인데, 이건 요즘 많이 등장하는 인수 우회 방법)
2020년 멜라녹스 인수 후 네트워킹 내재화에 완벽히 성공하며 지금의 독보적인 지위를 확보한 엔비디아이기에, 이번 인수 또한 매우 주목할 수 밖에 없다.
심플하게 요약해보면 프리필과 디코드로 나뉘는 추론 과정에서, 프리필을 Rubin CPX로 잡고 디코드를 그록 솔루션을 통해 강화하는 그림인가 보네.
이를 보면 메모리의 역할이 부품에서 설계의 중심으로 들어오는 큰 흐름이 다시 한번 포착되는 것 같기도.
“추론(inference)은 prefill과 decode로 분리(disaggregate)되고 있다. SRAM 아키텍처는, 성능이 주로 메모리 대역폭의 함수인 워크로드에서 decode에 독특한 장점이 있다. Groq에서 파생된 것으로 추정되는 Rubin CPX, Rubin, 그리고 이른바 “Rubin SRAM” 변형은 Nvidia가 각 워크로드별로 성능 대비 비용의 최적 균형을 만들기 위해 칩을 조합(mix and match)할 수 있게 해줄 것이다. Rubin CPX는 상대적으로 낮은 대역폭의 GDDR DRAM을 쓰지만 메모리 용량이 매우 높기 때문에, prefill 동안의 초대형 컨텍스트 윈도우에 최적화되어 있다. Rubin은 HBM DRAM으로 메모리 대역폭과 용량 사이에서 균형을 잡아, 학습(training)과 고밀도·배치(batched) 추론 워크로드의 주력(workhorse)이다. Groq에서 파생된 “Rubin SRAM”은 메모리 용량이 낮아지는 대가로 SRAM의 극도로 높은 메모리 대역폭을 활용해, 초저지연(agentic reasoning) 추론 워크로드에 최적화되어 있다. 마지막 경우에는 prefill에는 CPX 또는 일반 Rubin이 쓰일 가능성이 높다.”
“SRAM 아키텍처가 우리가 지금까지 본 어떤 GPU, TPU, 또는 어떤 ASIC보다도 훨씬 높은 tokens per second 지표를 찍을 수 있다는 것은 오래전부터 분명했다. 달러당 처리량(throughput per dollar)을 희생하는 대신, 개별 사용자당 지연(latency)을 극단적으로 낮추는 방식이다. 18개월 전만 해도 최종 사용자들이 이 속도에 돈을 낼 의향이 있는지는 덜 명확했다(SRAM은 배치 사이즈가 훨씬 작아서 토큰당 비용이 더 비싸기 때문). 이제 Cerebras와 Groq의 최근 결과를 보면, 사용자들이 속도에 기꺼이 돈을 낸다는 것이 아주 분명해졌다.”
“이로 인해 TPU, AI5, Trainium을 제외한 모든 ASIC들이 결국 취소될 것이라는 내 확신이 더 커졌다. Rubin의 3가지 변형과 그에 연관된 여러 네트워킹 칩들과 경쟁하는 데 행운을 빈다. 다만 OpenAI의 ASIC은 놀랄 만큼 좋을 것 같긴 하다(메타와 마이크로소프트의 ASIC들보다 훨씬 더).”
NVIDIA Jensen Huang Consumer Electronics Show Vegas - Rev
CES에서 가장 주목받는 주제가 메모리가 될줄이야.
“AI는 컴퓨팅 스택의 모든 계층을 재발명했습니다. AI가 기업들에 배포되기 시작하면 스토리지 방식 또한 재발명될 것이 당연합니다. AI는 SQL을 사용하지 않습니다. AI는 시맨틱(의미론적) 정보를 사용하며, 사용 과정에서 ‘KV 캐시(Key-Value Cache)’라고 불리는 일시적인 지식이나 기억을 생성합니다. 이것은 기본적으로 AI의 캐시이자 작업 기억(working memory)이며, 현재는 HBM 메모리에 저장됩니다.”
“GPU는 토큰 하나를 생성할 때마다 모델 전체를 읽어 들입니다. 전체 작업 기억을 읽어 토큰 하나를 생성하고, 그 토큰을 다시 KV 캐시에 저장합니다. 다음 토큰을 만들 때 또다시 전체 메모리를 읽어 GPU로 스트리밍하고 또 다른 토큰을 생성하죠. 토큰마다 이 과정을 반복합니다. AI와 긴 대화를 나누게 되면 이 컨텍스트 메모리는 엄청나게 커질 수밖에 없습니다. 모델 자체도 커지고 있고, 우리가 주고받는 대화의 횟수도 늘어나고 있기 때문입니다.”
“우리는 AI가 평생 우리와 함께하며 나눈 모든 대화를 기억하기를 바랍니다. 하지만 슈퍼컴퓨터를 공유하는 사람들의 수는 계속 늘어날 것이고, HBM 안에 들어가던 이 컨텍스트 메모리는 이제 더 이상 감당할 수 없을 만큼 커졌습니다. 작년에 우리는 그레이스 CPU를 호퍼나 블랙웰에 직접 연결해 컨텍스트 메모리를 확장했습니다. 하지만 그것조차 충분하지 않습니다.”
“다음 해결책은 당연히 네트워크를 통해 기업의 스토리지로 나가는 것이지만, 수많은 AI가 동시에 구동되면 그 네트워크 속도는 충분히 빠르지 않을 것입니다. 그래서 우리는 BlueField-4를 만들어 랙 바로 안에 매우 빠른 KV 캐시 컨텍스트 메모리 저장소를 갖출 수 있게 했습니다. 이것은 완전히 혁신적인 방식이며, 현재 토큰 생성량이 많은 AI 연구소와 클라우드 서비스 제공업체들이 겪고 있는 고통(네트워크 트래픽 문제)을 해결해 줄 것입니다.”
Nvidia at CES, Vera Rubin and AI-Native Storage Infrastructure, Alpamayo - Stratechery
“황 CEO의 설명을 보충하자면, 대규모 언어 모델(LLM)의 흥미로운 점은 우리가 챗봇과 대화하는 것처럼 느끼지만 실제로는 인간의 대화 방식과 매우 다르다는 것입니다. 인간은 대화 전체를 기억 속에 유지하며 반응하지만, LLM은 매 토큰을 예측할 때마다 문자 그대로 처음부터 모든 계산을 다시 수행합니다. 각 실행의 유일한 차이점은 이전 단계에서 생성된 토큰들이 다음 계산의 입력값에 포함된다는 것뿐입니다.”
“현재는 하나의 GPU가 대화 하나를 담당하며 메모리에 모든 컨텍스트를 담아 토큰 스트림을 빠르게 뱉어냅니다. 하지만 당신이 답장을 보낼 때, 기존에 대화하던 그 GPU가 당신을 기다리고 있을 가능성은 낮습니다. 대신 당신의 응답은 비어 있는 새로운 GPU에 할당되고, 대화의 전체 이력이 질문과 함께 전송되어 새로운 토큰 예측이 다시 시작됩니다. 이것이 우리가 며칠 전이나 몇 주 전의 대화를 다시 이어갈 수 있는 이유입니다. GPU 입장에서는 모든 대화, 아니 모든 토큰이 매번 ‘새로운 시작’이기 때문입니다.”
“대화의 문제는 토큰 저장에 필요한 메모리(정확히는 어텐션 레이어의 Key와 Value 값)가 컨텍스트 크기에 따라 선형적으로 증가한다는 점입니다. 이 때문에 지금까지 컨텍스트 창(지금까지 생성된 모든 토큰)에는 엄격한 한계가 있었습니다. 특히 최종 답변을 내놓기 전 엄청나게 많은 토큰을 생성하는 ‘추론 모델(Reasoning models)’이 등장하면서 이 문제는 더 심각해졌습니다. 또한 끊임없이 토큰을 생성하며 장시간 작동해야 하는 ‘에이전트’ 개념이 도입되면 문제는 더욱 악화됩니다.”
“황 CEO는 이를 해결하기 위해 새로운 아키텍처가 필요하다고 말하며, 개별 GPU에 전용으로 할당되어 각각 16TB의 추가 저장 공간을 제공하는 고속 솔리드 스테이트 스토리지가 포함된 베라 루빈 시스템 랙을 제시했습니다. 결정적으로, 이 스토리지는 ‘동서 평면(East-West plane)’에서 접근됩니다. 데이터센터 용어로 이는 전체 네트워크(남북 평면)를 거치지 않고 동일한 하위 시스템 내에서 데이터가 이동함을 의미합니다.”
“결과적으로 사용자는 획기적으로 더 긴 컨텍스트 창을 가질 수 있게 됩니다. 또한 이러한 컨텍스트 창을 여러 GPU가 공유할 수 있어, 협업하는 멀티턴(multi-turn) 에이전트들이 훨씬 더 효율적으로 정보를 공유할 수 있게 됩니다. 이는 엔비디아가 단순한 GPU 제조사가 아니라 ‘시스템’을 구축하는 회사임을 보여주는 훌륭한 사례입니다. 또한, 이는 속도를 위해 컨텍스트 창을 희생한 방식(Groq 등)과는 정반대로, 메모리 확장을 통해 성능을 극대화하는 전략입니다.”
#인프라
Lessons from History: The Great Railroad Buildout - Fabricated Knowledge
AI가 참 재밌는건 덕분에 인터넷, 모바일을 넘어서 산업 혁명, 석유 발굴, 철도 건설과 같은 인류 문명의 변곡점들을 공부하게끔 만든다는 것이다.
그리고 이런걸 공부할 때 마다 느끼는건 기술의 혁신과 금융의 발전은 함께 간다는 사실이다.
“철도 이야기가 반도체와 AI와 무슨 상관이 있을까요? 바로 인프라 건설 붐이기 때문입니다. 저는 AI 인프라 구축이 통신 버블보다는 철도 버블/자본 사이클과 더 닮았다고 생각합니다.”
“1. 정부의 개입 통신 버블(1996~2000): 당시의 투입 자본을 이미 넘어서고 있습니다. 철도와 마찬가지로 AI 역시 정부가 매우 지지적이며 핵심적인 역할을 하고 있습니다. 과거의 토지 보조금이나 현재의 ‘AI를 위한 맨해튼 프로젝트’ 구상은 매우 유사합니다. 정부와 기업의 이해관계가 이토록 일치하는 것은 철도 사이클의 특징입니다.”
“2. 공급이 수요를 창출하고, 가격 인하가 뒤따름: 가격은 수요의 궁극적인 동력입니다. 모델의 가격 하락은 중요한 지표입니다. 토큰 가격은 내려가야 하지만, 만약 ‘가격 전쟁’이 본격화된다면 이는 공급이 수요를 과도하게 앞지르고 있다는 신호(과잉 건설)입니다. 모든 자본 사이클에서 공급은 항상 미래 수요를 위해 먼저 구축됩니다.”
“3. 금융은 자본 사이클의 필수 요소: 금리 인상 사이클이 통신 버블의 종말과 맞물렸던 것은 우연이 아닙니다. 철도 사이클 역시 외부 자본의 제약(유럽 자본의 회수, 금본위제 위기 등) 때문에 끝이 났습니다. 우리는 지금 거대한 대출의 파도 앞에 서 있습니다. 자본주의가 이를 감당할 준비가 되었는지 자문해봐야 합니다.”
“4. 추적해야 할 지표들: 전체 하드웨어의 총량(Aggregate Fleet)과 총 자본 지출(Capex)은 매우 중요한 지표입니다. 하지만 가장 중요한 것은 가동률(Capacity Utilization)입니다. 철도 차량이 비어 있다면 게임은 끝난 것입니다.”
“결론적으로, 철도 버블은 현대적 관점에서는 이해가 안 될 정도로 과잉 건설되었습니다. 모든 철도가 오직 투기만으로 지어졌기 때문입니다. 하지만 그 과정에서 현대 금융 시스템이 탄생했고, 결국 인류의 물류 지형을 영구적으로 바꿨습니다. AI 역시 비슷한 경로를 걷게 될지 지켜봐야 할 것입니다.”
AI 데이터센터 전력에서 일어나고 있는 변화: 전력망에서 (Grid) → 임시 전력원 설치에서 (Bridge Power) → 영구적 자급자족으로 (Fully Behind the Meter)
“일론은 기본적으로 제1원칙에서 생각했습니다. “AI 레이스에 참여하고 싶은데 내가 뒤처져 있다, 어떻게 하면 누구보다 빨리 데이터센터를 지을 수 있을까?”라고 생각한 거죠. 흥미로운 점은 그때가 24년 초나 23년 말이었는데, 그는 오라클 같은 여러 클라우드 기업들과 대화하고 있었습니다. 원래 xAI는 텍사스 애빌린(Abilene)의 스타게이트 부지를 받기 위해 오라클과 접촉하고 있었죠.”
“사람들은 그에게 “2025년 중반에나 전력을 받을 수 있을 것”이라고 말했습니다. 그래서 xAI는 “뭔가 대책을 세워야겠다”고 생각했고 제1원칙에서 모든 것을 다시 생각했습니다. 데이터센터 부지 선정부터요. 새로 짓지 말고 기존 부지를 찾자고 했죠. 그래서 멤피스에 있는 오래된 세탁기나 가전 공장 부지를 찾았습니다. 그리고 에너지 측면에서는 “그리드는 너무 느릴 테니 스스로 전력을 생산해야 한다, 그것도 빨리 해야 한다”고 생각했습니다. 가장 빨리 전력을 얻는 방법이 뭘까? 유틸리티 규모의 터빈을 쓰는 건 시간이 너무 걸리니, 그는 모든 벤더와 대화했고 재고가 있는 터빈 임대 업체를 찾았습니다. 임대용 터빈들이 많이 있었죠. 그들은 빌려주고 싶어 했고, 일론은 “그거 가져올 수 있나요? 설치가 꽤 빠르네요. 몇 주면 된다고요? 현장에 배치해서 전력을 생산하면 정말 빠르겠군요”라고 했습니다. 그는 그것이 새로운 부지에 에너지를 공급하는 가장 단순하고 빠른 방법이라고 생각했습니다. 그것이 본질적인 이야기입니다. 제1원칙에 따라 200~300메가와트 규모의 GPU 클러스터 데이터센터를 어떻게 가장 빨리 지을 것인가? 그는 단 4개월 만에 해냈습니다. 스스로 에너지를 만들고, 기존 부지를 활용하는 플레이북을 만든 거죠.”
“재밌는 건 이에 대해 두 가지 반응이 있었다는 겁니다. 한쪽에는 “아니야, 그건 미친 짓이야, 우리 업계는 그렇게 돌아가지 않아”라고 생각하는 전통적인 데이터센터 사람들이 있었습니다. 당시 저는 여러 컨퍼런스에 가고 있었는데 모든 사람이 “아니, 아무도 저렇게 해서는 안 돼, 부동산 관점에서 그건 올바른 방식이 아니야”라고 말했습니다. 하지만 다른 세계, 즉 현재 시장 점유율을 점점 높여가고 있는 AI 세계가 있었습니다. 오픈AI, 앤스로픽, 모든 AI 랩들, AI 커뮤니티의 모든 사람은 “일론은 천재야, 그게 바로 지금부터 우리가 데이터센터를 지어야 할 방식이야”라고 생각했습니다. 흥미로운 점은 신규 구축에서 AI 랩들의 비중이 엄청나게 늘어났고, 이제 그들이 의사 결정권을 쥐고 사람들에게 어떻게 해야 하는지 지시하고 있다는 것입니다. 그래서 지금 산업 전체가 그 사고방식에 적응하고 있는 겁니다.”
“전력 공급 승인과 대규모 부하 요청 차트를 다시 보면 걱정되는 부분은 상황이 한 방향으로만 가고 있다는 겁니다. 그리드는 점점 더 제약을 받고 있습니다. 원래 27년 말이면 유틸리티 전력을 받을 수 있을 거라 생각했던 사람들에게 갑자기 28년 말, 29년 말, 혹은 2035년이 될 거라는 통보가 가고 있습니다. 그리드는 점점 더 신뢰할 수 없게 되고 있고, 이는 사람들이 본질적으로 ‘완전 비하인드 더 미터(fully behind the meter)’ 데이터센터를 계획하게 만듭니다.”
“(완전 비하인드 더 미터 데이터센터란 무엇이며, 일론이 xAI에서 했던 것과 비교하면 계획이 어떻게 다른가요?) 이론적으로는 전력 비용을 낮추고 오래 쓸 수 있는 기계를 원하겠죠. 그래서 주로 유틸리티 규모의 터빈을 사용하게 될 겁니다. 소형 모듈형 터빈이나 엔진에서 우리가 오랫동안 알고 지낸 대형 시스템으로 넘어가는 거죠. 20~30년 동안 아주 싸게 전력을 생산할 수 있는 시스템입니다. H-클래스 CCGT[복합 화력 가스 터빈]라고 부르는 것들인데, 60% 이상의 효율을 냅니다. 기저 부하(base load) 전력으로 이상적이죠. 그리고 스스로 중복성을 관리해야 하고 시스템은 좀 더 복잡해질 겁니다.”
“분명히 말씀드리자면, 현재 실제로 그런 사례가 가동 중인 것은 아니기 때문에 지켜봐야 합니다. 오늘날의 모든 현장 가스 발전 배치는 브릿지 파워 목적입니다. 하지만 우리가 사이트 계획, 허가 신청 등을 분석해 본 결과, 2027년이나 2028년경의 일부 데이터센터들은 아예 그리드를 포기하고 현장에 자체 발전소를 세울 계획을 하고 있다는 것을 이미 알 수 있습니다.”
→ “보통 전력과 그리드를 늘리는 방법을 생각할 때 대부분의 사람은 공급 측면의 사고방식에서 시작합니다. 발전소를 지어야 하고 송전선을 지어야 한다고 하죠. 그런데 여기서 일어나는 일은 수요가 너무나 급격하게 증가해서 수요를 창출하는 사람들이 스스로 공급을 가져오고 있다는 겁니다. 그리고 그 공급이 확보되면 자연스럽게 “우리 1기가와트 데이터센터를 위해 중복성을 구축할 수도 있고, 아니면 데이터센터 업체들끼리 협력해서 중복성 측면에서 서로 도울 수도 있겠다”는 생각으로 이어지며 갑자기 새로운 그리드가 만들어지는 거죠. 공급 측면이 아니라 수요 측면에서 시작해서요.”
#핀테크
System Update: The future of finance is on Coinbase
‘Everything Exchange’라는 전략하에 로빈후드와 같은 길을 걸어가는 코인베이스. 자산의 토큰화는 정해진 미래라는 의미.
“오늘 우리는 코인베이스에서 금융의 미래를 선도할 여러 신제품을 출시했습니다. 여기에는 코인베이스 메인 앱 내 주식 거래 및 예측 시장 서비스 시작, 단순화된 선물 및 무기한 선물 인터페이스, 생성 직후의 모든 솔라나 자산 거래 기능, 기본 토큰 판매(Primary token sales) 등이 포함됩니다. 또한 온체인 ‘에브리싱 앱(Everything app)’인 Base App의 글로벌 출시와 코인베이스 비즈니스의 정식 서비스도 시작되었습니다.”
“금융의 미래가 온체인에 있다면, 주식 거래의 미래도 마찬가지입니다. 우리는 결국 모든 것이 토큰화될 것이라고 믿으며, 코인베이스에 주식을 도입하는 것은 토큰화된 주식을 가능하게 하는 중요한 이정표입니다. 토큰화된 주식을 통해 전 세계 어디서나 24시간 거래하고, 소유한 주식을 온체인에서 사용하며, 즉시 결제까지 할 수 있게 될 것입니다.”
“이 여정을 시작하기 위해 우리는 실물 자산(RWA) 토큰화를 위한 새로운 기관용 엔드투엔드 플랫폼인 코인베이스 토큰나이즈(Coinbase Tokenize)*를 출시할 계획입니다. Tokenize는 코인베이스에서 토큰화된 주식에 접근할 수 있도록 하는 모든 필수 인프라를 결합할 것입니다. 내년 초 업데이트를 기대해 주세요.”
The Protocol Economy: Hashed 2026
스테이블코인은 아마도 B2B 단에서 한단계 더 도약하지 않을까 싶다.
투자 논지: B2B 스테이블코인 인프라는 ‘결제’에서 끝나지 않고 ‘기업 운전자본 레이어’로 진화할 것이다.
2026년에는 블록체인 인프라 자체는 더 이상 차별화 요소가 아닐 것이다. 스테이블코인은 기술적 선택지라기보다 전제 조건에 가까워지고 있고, 단순히 L1/L2를 출시하거나 새로운 레일을 주장하는 것만으로는 차별성을 만들 수가 없다. 진짜 비대칭적인 해자는 이제 스테이블코인 활용을 통해 기업의 현금 흐름(cash cycle)에 어떻게 통합되느냐, 즉 기업 금융의 워크플로우 안에서 어떤 역할을 하느냐의 구간으로 이동하고 있다.
스테이블코인은 더 이상 단순한 결제 수단이나 트레이딩에 사용되는 자산으로만 정의되지 않을 것이다. B2B 분야에서는 공급자 및 벤더 네트워크의 정산 및 청산, FX 헤징, MNC의 자회사 간 자금 네팅, 트레저리 라우팅과 일일 유동성 포지셔닝 등 전통적인 기업 재무 업무의 단위(unit of account)로 작동하기 시작할 것이다. 이 과정에서 온체인 유동성은 24/7로 움직이는 운전자본(working capital)이 될 것이다. 특히 B2B 스테이블코인의 사용이 기존 트레저리 운영(자동화된 AP/AR, 트레저리 단위의 캐시 스윕, 법인 간 네팅 및 회계/자금 통합)을 닮아가고 아웃퍼폼하기 시작할 때, 비로소 대대적인 차원의 채택이 진행될 것이다.
이 기회는 은행이나 핀테크를 대체하는 데 있지 않다. 오히려 상업은행들이 UX와 워크플로우를 임베디드 파이낸스에 위임할수록, 정산, FX 맟 트레저리 관리 등 백엔드는 비교적 느리고 비효율적인 채로 남겨지게 될 것이다. 이 지점이 바로 스테이블코인이 보이지 않게 침투할 수 있는 자리일 수 있다. 핵심 플레이어들은 머천트나 최종 고객을 소유하기보다, 임베디드 파이낸스와 은행이 직접 구축하기 부담스러워하는 규제 친화적/엔터프라이즈급 트레저리 백엔드를 운영하는 쪽에 가깝다.
이 모델에서 채택을 결정하는 주체는 CFO와 재무팀이다 (때때로는 CTO와 기술팀일 수도 있다). 따라서 성공 요인은 단순히 결제 볼륨이나 브랜드 인지도, 세부적인 기술적 차별성에서 나오지 않을 것이다. 중요한 질문은 오히려 다음과 같다:
-다국가 및 다통화 환경에서 규제된 유동성을 실제로 이동시킬 수 있는가?
-온체인 자금 흐름을 ERP, 회계, 컴플라이언스 시스템과 자연스럽게 연결할 수 있는가?
-크립토 레일과 기존 핀테크 레일 사이의 정산 과정에서 운영 심리스한 루프를 만들어낼 수 있는가?
-운영 단에서 엔터프라이즈 수준의 감사 가능성, 추적성, 프라이버시 기준을 충족하는가?
궁극적으로 해자는 스테이블코인 레일이라는 기술 자체가 아니라, 그 전제 위에 지어진 규제, 운영 및 법무 노하우의 축적에 있을 것이다. 글로벌 유동성을 실제로 운용해본 경험, 규제 기관과의 신뢰 관계, 그리고 시간이 쌓이면서만 형성되는 운영 복잡성이 진입장벽이 될 것이다. 미국, 유럽, 아시아 주요 금융 허브에서 스테이블코인 규제 프레임워크가 구체화될수록, 기업들은 파일럿을 넘어 전면 채택의 단계로 이동할 것이다. 그 결과 스테이블코인은 전면에 드러나지 않지만, 기업 금융의 필수 운송 레이어로 자리 잡게 될 것이다. 크립토가 엔드유저에 직접적으로 드러나지는 않지만, 제거할 수 없는 인프라가 되는 길이다.
핀테크 투자의 명가 Ribbit Capital은 앞으로의 시대를 ‘Token Revolution’의 시대로 표현.
토큰화란 데이터·정체성·돈·자산 등을 기계가 읽고 행동할 수 있게 만드는 과정이고, 그 토큰들이 AI 에이전트를 만들고 구동하는 핵심 자원이 된다고 본다. 이는 AI와 크립토를 함께 아우르는 개념.
리포트 GPT 요약:
“Ribbit의 2025년 6월 Token Letter는 AI 에이전트가 세상을 ‘이해하고(토큰화) → 결정하고 → 실행’하기 위해 필요한 모든 입력·권한·자원(=토큰)을 ‘공장(토큰 팩토리)’에서 정제·조합·운용하면서, 산업의 운영체계(Vertical Token Systems)와 금융 인프라(자산 토큰/스테이블코인), 그리고 정보 인프라(진실·주의 시장)까지 재편한다는 큰 그림을 제시합니다.”
“리포트 말미에는 Ribbit이 무엇을 “헌팅”할지 비교적 직설적으로 적습니다. 요지는 에이전트를 ‘퍼스트클래스 고객’으로 대하는 스택(결제/신원 등), Vertical Token Systems, 에이전트-퍼스트 CRM/고객 인터랙션, 에이전트 신원·데이터 소유(특히 memory tokens), 보편적 개인 재무 비서, 언더리소스(크리에이터/SMB)에 슈퍼파워 제공, 토큰화 자산 인프라(발행/처리/관리), 1%만 누리던 서비스를 대중화, 예측/콘텐츠 시장 같은 ‘기계를 위한 신문’, 자율 에이전트용 자원(컴퓨트/데이터/거버넌스/평판), 그리고 강한 IP 기반의 real-world token factories입니다.”
“요약하면: Ribbit은 토큰 혁명이 지식(know-how)을 민주화하고, 그 결과 권력과 돈의 배분이 크게 바뀌며, 이 셋의 관계가 재조정된다고 봅니다.”
#금융
“역사적으로 승자들은 흩어진 정보를 모아 정돈했습니다. 로이터는 지리적 가격을, 쿼트론은 시계열 가격을, 블룸버그는 구조화된 데이터를, 알파센스는 비구조화된 텍스트를 통합했습니다.”
“이제 AI 시대의 승자는 ‘엔트로피를 활용하는 자’가 될 것입니다. 단순히 하나의 정답을 찾는 것이 아니라, 수십 개의 AI 에이전트를 가동해 다양한 관점에서 리스크를 점검하고(평가), 파편화된 공급업체의 데이터를 실시간으로 엮어내는(오케스트레이션) 능력이 중요해집니다.”
“정보 시장의 비즈니스 모델은 본질적으로 변하지 않았습니다. 7세기의 마라처럼, 시장 참여자들 사이의 정보 비대칭성을 줄여주는 인프라를 구축하는 자가 가치를 영속적으로 점유할 것입니다.”
“이제 정보의 공급 과잉이 아니라 ‘인사이트의 공급 과잉’ 시대가 되었습니다. 승부처는 데이터를 많이 가지는 것이 아니라, AI가 내놓은 여러 해석 중 무엇이 옳은지 판단하는 ‘평가(Evaluation)’와 여러 데이터 소스를 연결하는 ‘오케스트레이션(Orchestration)’으로 옮겨가고 있습니다.”
Capital in the 22nd Century - philip trammell
피케티의 경제 불평등 이론을 AI로 인한 완전 자동화가 도래할 미래에 대입하여 재해석한 글. 즉, 자본 수익률이 경제 성장률을 앞서 불평등이 심화된다는 이론이 과거에는 틀렸을지 몰라도 AI와 로봇이 노동을 완전히 대체할 미래에는 적중할 수 있다고 이야기한다.
나는 피케티의 21세기 자본을 읽어보지 않았는데, 어쩌면 지금이 읽기 적절한 시점일지도 모르겠다는 생각이 드네.
“2013년 저서 ‘21세기 자본’에서 사회주의 경제학자 토마 피케티는 강력한 재분배가 없다면 경제적 불평등이 세대를 거쳐 무한히 증가하는 경향이 있다고 주장했습니다. 부유한 사람들은 가난한 사람들보다 더 많이 저축하고 투자 수익률도 더 높기 때문입니다.”
“당시 많은 이들이 지적했듯, 이는 과거에 대한 잘못된 해석일 가능성이 높습니다. 노동과 자본은 서로를 보완합니다. 부유한 사람들이 자본을 계속 축적할 수는 있지만, 그것을 사용할 ‘손’이 부족하면 망치(자본)의 가치는 떨어지고, 망치가 흔해지면 손(노동)의 가치는 올라갑니다. 따라서 자본 축적은 이자율을 낮추고 임금을 높입니다. 이 효과는 충분히 강력해서 자본 축적만으로 인한 불평등은 스스로 교정되어 왔습니다.”
“하지만 첨단 로보틱스와 AI의 세상에서는 이 교정 메커니즘이 무너질 것입니다. 즉, 피케티가 과거에 대해서는 틀렸을지 몰라도 미래에 대해서는 맞을 것이라는 점입니다. AI가 자본을 노동의 완전한 대체재로 만든다면, 전환기에 가장 부유했던 사람들 혹은 그 후계자들이 결국 거의 모든 것을 소유하게 될 것입니다.”
AI and the Human Condition - Stratechery
그리고 이에 대한 벤 톰슨의 아주 합리적인 코멘트 (아래)
관련해서, 나는 요즘 감도(taste)라는 용어를 자주 사용한다. AI 시대에는 좋은걸 알아보고 만들어내는 감도가 뛰어난 사람들이 중요해질 것 같아서.
“저는 파텔과 트램멜의 논리를 이해하지만, 이것이 지금 당장 해결해야 할 문제인지에 대해서는 회의적입니다.”
“1. 모두를 위한 풍요: 그들이 상상하는 세상은 모든 사람에게 놀라운 세상일 수 있습니다. AI가 모든 것을 할 수 있다면 음식, 의류, 서비스 등 모든 것을 가질 수 있다는 뜻입니다. 모든 물질적 욕구가 충족된다면 로봇을 직접 소유하지 않는 것이 중요할까요?
“2. 재산권의 변화: AI가 그토록 환상적인 능력을 갖췄음에도 여전히 2025년 방식의 재산권 법망에 갇혀 인간의 통제를 받는다는 것은 부자연스럽습니다. 오히려 통제 불가능한 AI라는 파멸 시나리오가 더 현실적이며, 풍요의 길로 접어든다면 재산권에 대한 우리의 집단적 이해 자체가 크게 변할 것입니다.”
“3. 역사적 전례: 인류 역사상 노동의 급격한 변화는 늘 있었습니다. 1810년 미국 인구의 81%가 농업에 종사했지만, 200년 후에는 1%에 불과합니다. 인간은 기계로 대체되었지만 식량은 풍부해졌고 훨씬 저렴해졌습니다. 인간은 손을 놓고 있었던 것이 아니라, 이전에는 상상조차 할 수 없었던 완전히 새로운 종류의 일을 만들어냈고, 그 가치는 이전보다 훨씬 높았습니다.”
“예를 들어, 전문 팟캐스터 같은 직업 말입니다! 30년 전에는 팟캐스트라는 것 자체가 없었지만, 지금 파텔과 저는 마이크에 대고 말을 하며 인터넷의 제로 한계 비용 배포 기술을 활용해 자본을 축적하고 있습니다. 물론 로봇이 파텔이나 저보다 팟캐스팅을 더 잘하게 될 수도 있습니다. 하지만 저는 회의적입니다. 제 경험상 ‘인간적인 요소’는 매력적인 콘텐츠를 만드는 데 필수적입니다.”
“콘텐츠 제작의 역학은 AI와 정확히 반대입니다.”
- 인간: 개별 인간이 대규모 대중에게 도달하는 능력.
- AI: 컴퓨팅 자원을 확장하여 개인에게 맞춤형 결과를 제공하는 능력.
“또한 AI의 긍정적인 측면 중 하나는 ‘아름다움’에 대한 재평가와 투자입니다. 산업 시대의 비극 중 하나는 건축물 등에서 아름다움을 찾아볼 수 없게 되었다는 점입니다. 수백 년 전에는 복잡한 대성당을 지었는데 왜 지금은 성냥갑 같은 건물만 지을까요? 노동의 가치가 너무 높아져서 수천 명의 인력을 투입하는 것이 경제적으로 불가능해졌기 때문입니다. 그렇다면 AI로 인해 노동의 가치가 낮아진다면, 인간은 다시 아름다움을 창조하는 데 전념할 수 있지 않을까요? AI 아트가 흔해질수록 인간의 예술은 그 출처(provenance) 덕분에 더욱 가치 있게 될 것입니다.”
#투자
The Last Human Edge - Colossus
“라포트가 프라이스로부터 성장 투자에 대해 배운 것 이상으로 알아낸 것은, 모델만큼이나 사람이 중요하다는 것이었습니다. 그는 오너처럼 생각하고, 사업을 점진적으로 개선하며, 자본을 자기 돈처럼 배분하는 운영자를 찾았습니다. 그는 다음 분기를 예측하려 하지 않았습니다. 그는 해자(moat)를 구축하고 방어할 수 있는 희귀한 창업자나 CEO를 식별하려고 했습니다.”
“그는 제가 본 중 패턴 인식에 있어 가장 뛰어난 두뇌를 가진 사람 중 한 명입니다.” 마이로드가 말했습니다. “그는 서로 아무 관련이 없는 두 개의 다른 비즈니스를 보고 패턴을 찾아낼 수 있습니다. 그것이 그에게 정말 차별화된 수준의 확신을 줍니다.” - 마이로드, 부킹홀딩스 의장
“최고의 투자자는 패턴을 수집하는 사람들입니다.” 그녀가 말했습니다. “그런 패턴을 구축하는 데는 오랜 시간이 걸립니다. 패턴을 구축하는 속도를 가속화할 수 있을수록 더 좋은 투자자가 됩니다. 제가 그를 만났을 때, 그는 이미 다른 누구도 갖지 못한 패턴 세트를 축적해 둔 상태였습니다.”
“엘런보겐은 패턴을 찾고 있었는데 놀라운 사실을 발견했습니다. 50년과 수천 건의 투자, 여러 번의 시장 사이클, 그리고 각기 다른 스타일을 가진 매니저들을 거쳤지만, 단 20개의 주식만이 중요했습니다. 펀드가 벌어들인 모든 수익은 일찍 발굴되어 적당한 포지션을 혁신적인 결과로 바꿀 만큼 오래 보유한 20개 회사에서 나왔습니다. 나머지는 아무것도 아니었습니다.”
“데이터에 따르면 어느 10년 기간이든 약 40개의 주식이 연 20%의 부를 복리로 창출합니다. 4,000개 중 40개. 상장 기업의 1%만이 위대해지며, 그중 약 80%는 뉴 호라이즌스가 낚시를 하던 바로 그 영역인 소형 회사로 시작했습니다. 그는 게임의 전부가 이런 작은 비즈니스를 일찍 찾아서 끝까지 보유하는 것임을 깨달았습니다.”
“첫째, 모든 복리 성장 기업은 투하자본수익률(ROIC)이 증가하는 모습을 보였습니다. 그들은 커질수록 더 좋아졌고, 규모를 얻을수록 경쟁을 덜 마주했으며, 지속적으로 높은 수익률로 이익을 재투자할 수 있었습니다. 트위터나 넷플릭스 같은 폭발적인 비즈니스뿐만이 아니었습니다. 오라일리 오토모티브(O’Reilly Automotive), RBC 베어링스(RBC Bearings), 베일 리조트(Vail Resorts) 같은 덜 화려한 이름들도 포함되었습니다.”
“둘째, 이 희귀한 비즈니스들은 변동성이 극심했습니다. 20%씩 복리 성장하던 10년 중 어느 해에는 62% 하락하기도 했습니다. 종종 이것은 대부분의 주식이 하락하는 시장 붕괴 기간이 아니라, 비즈니스가 더 큰 무언가가 되려고 시도하는 전환기 동안 일어났습니다. 복리 성장 기업이 되는 모든 회사는 여정의 중간에 처벌을 받았습니다. 비결은 실패하는 회사와 전환하는 회사를 구별하고, 그 차이를 견뎌낼 확신을 갖는 데 있었습니다.”
“그는 회사의 여정을 2막으로 생각하기 시작했습니다. 1막(Act 1)은 회사가 제품-시장 적합성을 입증하고, 큰 규모의 시장을 확인하고, 단위 경제가 작동함을 증명했다는 것을 의미했습니다. 2막(Act 2)은 도약이었습니다. 중요한 신제품, 주요 신시장, 원래 사업보다 근본적으로 더 큰 무언가가 되는 것입니다.”
“넷플릭스의 1막은 DVD 우편 대여였습니다. 2막은 스트리밍이었습니다. 그 사이에는 80만 건의 구독 취소와 75% 하락한 주가가 있었습니다. 그 잔인한 전환기가 바로 기업이 복리 성장 기업이 되거나 시도하다 사라지는 지점이었습니다. 이제 언어를 갖게 되자, 그는 프로세스를 구축할 수 있었습니다. 그는 펀드를 1막 기업과 2막 기업으로 나누었습니다. 뉴 호라이즌스의 3분의 2는 베일이나 RBC 베어링스처럼 이미 2막에 있는, 그가 ‘지속 가능한 성장(durable growth)’ 비즈니스라고 부르는 곳에 투자했습니다. 나머지 3분의 1은 도약할 수 있는 특성을 보이는, 아직 1막에 있는 신흥 성장 기업을 목표로 했습니다.”
“초과 수익은 새로운 포지션이 아니라 시간이 지나면서 발전하는 보유 종목에서 나옵니다. 그는 회사가 도약에 실패하면 포트폴리오를 가지치기하여 장기적으로는 훨씬 적은 수의 비즈니스를 소유할 것으로 예상했습니다.”
나는 성공한 사람들의 취미가 늘 궁금하고 재밌다 - 자허브르
불확실한 게임에서 리스크를 감수하며 오래 버틴 사람이 결과적으로 큰 보상을 얻을 가능성이 높은데, 그런 사람들이 대체적으로 어떠한 특성을 지니는지 담겨있는 글.
“결국 격차를 만드는 것은 재능이 아니라 불확실성을 대하는 태도다. 무엇을 하며 고통을 견디고 보상이 보장되지 않는 시간을 보낼 것인가? 그들의 고통 견디기는 장인 정신 + 오덕 지수 + 말도 안되는 깊이로 설명되는 ‘방망이 깎는 노인의 깎는 기술’로 축적된다. 그들은 이 기술을 가지고 본업뿐만 아니라 본업 외에도 퍼붓는다.”
#마지막으로
감도가 높다는건, 이런거라고 생각한다.
“잘 설계된 선택은 시간 t라는 변수를 품은, 자유에 관한 좋은 함수 x=f(t)와 같다. 그 함수를 시간에 대해 적분(∫xdt)하면 더 큰 자유가 나온다. 다시 말해 좋은 함수를 가진 자에게, 더 큰 부를 위해 필요한 건 오로지 시간의 흐름뿐이다. 그 함수를 쓰는 데 필요한 것이 지식이다. 지식이 부족할수록 불확실성과 운의 비중은 커진다. 어떤 사건이 발생할 확률을 판단할 때 지식이 없는 사람은 0~100% 로 측정을 하지만(완전히 운에 맡기지만), 지식이 더 있는 사람은 확률의 측정 정밀도를 45~58% 구간으로 좁힐 수 있고, 더 지식이 있는 사람은 비로소 51~52% 구간까지 좁힐 수 있다. 50% 이상의 확률로 이득이 된다고 확신할 수 있는 선택만을 반복하면, 처음 서너번은 누적으로 손해를 볼 수 있지만, 큰 수의 법칙에 따라 충분한 시간이 흐르면 계속 부가 늘어날 수밖에 없다.”