
Insight #118_바이브 코딩, 앤트로픽 vs 국방부, 전쟁과 AI, 멀티 에이전트, 다리오 아모데이, 로컬 vs 클라우드, 메모리와 낸드, AI 에이전트와 스테이블코인, 취향 그리고 감도
이번 한달 사이에도 AI와 관련하여 이런저런 소식들이 많았지만, 저 개인적으로는 이런 뉴스들보다도 바이브 코딩으로 이것저것 필요한 것들을 뚝딱뚝딱 만들어내면서 AI의 강력함을 몸소 체감하는 한 달을 보냈습니다.
정말이지 매일마다 ‘이게 되네?’를 체감하면서 살아가고 있는데, 마치 마법사가 된 기분입니다. 예전에 코딩하는 사람들의 인터뷰를 보면 자기가 생각하는걸 구현할 때 짜릿해하는 장면들이 많았었는데, AI 덕분에 그러한 짜릿함을 비개발자인 제가 느낄 수 있게 되었습니다.
정말이지 말이 안되는 세상 속에 살아가고 있는 것 같은데, 설레임과 동시에 한편으로는 무서운 세상인 것 같습니다. 더더욱 정신 바짝 차리고 세상의 발전을 따라가야만 할 것 같습니다.
오늘은 AI, 하드웨어, 핀테크에 대해 다룹니다.
뉴스레터 외에도 텔레그램 및 블로그에서 저의 생각을 접해보실 수 있습니다.
#AI
Dylan Patel: They Don’t See It Coming
10000% 동의. 처음에는 개발자 대체 도구인줄 알았으나, 이걸 내가 직접 사용하면서 느끼는건 나 같은 비개발자가 활용할 영역이 정말 무궁무진하다는 점이다. 딱 한번 느껴보면 새로운 세상이 펼쳐진다.
“사람들은 클로드 코드나 코덱스를 코딩 도구라고 인식하는데, 사실 그렇지 않습니다. 프로그래머가 아닌 사람이 일부러라도 이런 도구를 써보면 엄청난 생산성 향상을 얻을 수 있어요.”
“ChatGPT와 이런 것들의 차이는 완전히 다릅니다. 클로드 코드, Cursor 에이전트 모드, Codex 같은 건 전부 에이전트 오케스트레이션 시스템입니다. 그리고 그걸 통해 뭐든 시킬 수 있고요. 자연어로 말하면 실제로 일을 하러 가니까요. 물론 소프트웨어를 만들 수도 있고요.”
“사실 도메인을 이해하고 있는 사람이라면, 자신이 원하는 것을 그저 설명하고, 결과물을 확인한 뒤, 계속해서 반복하고 수정해 나갈 수 있습니다. 그러니 이건 프로그래밍이 아니에요. 비즈니스 로직이 코드화(구현)되는 과정인 거죠, 안 그런가요?”
EP 85. OpenClaw와 2026년 2월의 신호들 - AI 프론티어
한줄로 표현하면 내가 하는 일의 상당 부분을 컴퓨팅으로 치환이 가능해지는 시대다. 그러니 이걸 빠르게 적응해서 해내는 사람들이 이 시대를 이끌어갈 수 밖에 없다고 본다.
그리고 역설적으로 나의 일을 AI로 대체할수록 새로운 할 일들이 계속해서 떠오르기 때문에 더더욱 바빠지는 것 같고, 오히려 더욱 중요한 일에 많은 리소스를 쓰게 되는 것 같다. (이러한 이야기들이 예전에는 이해는 되지만 납득이 완전히 되는건 아니었는데, 이제는 100% 납득이 된다.)
“코드를 쓰고 있는 게 의미가 없어진 세상이고, 요새 돌아다니면서 소프트웨어 엔지니어 분들을 만나보면 그런 이야기 심심치 않게 하시는 것 같아요.”
“비꼬는 분들은 “지금 소프트웨어 엔지니어가 최고의 직업이다. 왜? 다 에이전트한테 일 시키고 자기는 비싼 월급 받으면 되니까”라고 합니다. 그거 하나고, 두 번째로는 “이제는 이직하면서 연봉 올리는 거는 불가능하구나”라는 걸 다 인지하고 있는 것 같아요. 시니어에서 주니어 레벨까지 그냥 지금 있는 좋은 회사에서 어떻게 큰 문제가 안 생기고 무언가로 전환(Transition)할 수만 있다면 그나마 다행이라는 이야기들을 심심치 않게 하고 계시거든요.”
“그러면서 어떻게 해야 되냐라는 것들을 물어보시는데, 이 부분에 대해서 소프트웨어 엔지니어들이 갖고 있는 우울함, 그다음에 Agentic Coding이나 이 Vibe Coding을 가지고 누가 가장 큰 득을 보고 있느냐 이런 것들을 보면 어떻게 생각하실지 모르겠는데 제가 주변에서 관찰을 해 본 바로는 제일 잘 하시는 분들은 소위 엔지니어링에 대한 부분에 이 암묵지와 잔뼈가 굵은 사람들입니다.”
“아까 승준 님이 OpenClaw이나 Pi 만들었던 사람들 전부 다 2~30년의 경력자라고 말씀하셨던 것처럼, 그런 경력을 가지고 있으면서 플러스 비즈니스 센스, 즉 뛰어난 사업가 감각이 있는 사람들이 지금 가장 큰 수혜자들입니다. 이 사람들은 본인이 생각하는 어떤 문제에 대한 해결책과 사업화하는 과정 자체를 그냥 AI로 막 쓰고 있거든요. 거칠 게 없어요. “못할 일이 있을까요”라는 생각을 하면서 빌딩하느라고 지금 정신이 없습니다. 그리고 빌딩만 하는 게 아니라 이것들을 어떤 식으로 사업으로 바꿔야 될지에 대한 고민들도 하고 계시거든요. 그분들도 명확하게 ‘내가 만들 수 있는 거, 다른 사람도 다 만들 수 있는데 나만 만들 수 있는 거’에 대한 고민들을 지금 하고 계시는 거거든요.”
“그래서 이러한 이야기들이 아마 올해 후반으로 갈수록 창업계라든지 Y Combinator의 어떤 행사라든지 그런 것들을 지배하는 키워드가 될 거라는 생각은 들어요. 그래서 그들이 가장 큰 수혜자들이고, 두 번째 수혜자가 소프트웨어 엔지니어일 것 같은데 전혀 아니더라고요. 두 번째 수혜자는 누구냐면요, 소프트웨어는 하나도 할 줄 모르는데 그 해당 도메인에 대한 문제 의식과 그에 대해서 암묵지를 가지고 있는, 소위 심하게 요약하면 ‘문과’입니다.”
“그냥 심하게 어떤 상징성을 부여하기 위해서 저희가 문과라는 이야기를 쓴 거죠. 그분들이 두 번째로 잘하는 분이에요. 이분들은 뭘로 하냐, Ralph Loop로 해요. 뭐가 됐든지 간에 처음 시작하는 시작점을 만들 줄 알고, 이게 끝났을 때 어떤 게 돼야 된다라고 하는 평가 지표(Evaluation Metric)에 대한 가정을 하실 수 있는 분들이죠. 그러면 그거 딱 밀어넣고 그냥 될 때까지 “해줘, 해줘, 해줘” 엔터 누르는 거죠. 그러면 그 사이에서 모델이, 그냥 이 문제를 의뢰한 사람들이 가지고 있었던 혼돈의 영역이나 혹은 생각해 보지 않았던 그런 영역들까지 모델이 전부 서치하고 시뮬레이션해 보고 실수를 해서, 결국 Evaluation Metric을 만족하지 않으면 그냥 안 하고, 그래서 어떻게든 찾아와요. 수많은 토큰을 태워서 진화의 과정을 통해서 답을 가져옵니다. 그래서 이분들까지는 저는 수혜자인 것 같아요.”
“세 번째 수혜자는 사실 수혜자라는 표현이 부족하고 피해자라는 표현이 제일 맞을 것 같은데, 거의 절대 다수의 엔지니어들이 피해자예요. 이분들이 지금 본인이 가지고 있었던 스킬, 도구, 가지고 있었던 어떤 지적인 우위, 이런 것들의 가치가 심하게 얘기하면 거의 0에 떨어진 상황이거든요. 그리고 뭘 많이 만들 줄은 아시는데 이 만드는 것들이 누군가에게 어떻게 써야 된다라고 하는 그 구간에 대한 생각이 없으세요. 그래서 Product은 많이 만드는데 그냥 필요 없는 Product들이 양산되고 있는 거죠.”
“그래서 저희가 긴 얘기를 했지만 마지막으로 정리를 하면, 미친 듯이 빨리 변하고 있습니다. 미친 듯이 빨리 변하고 있고 살아갈 수 있는 방법은 그 변화의 속도와 같이 사는 것밖에는 방법이 없는데, 그럼 그 변화의 속도에 따라가면서 우리가 프런티어 랩이 아닌 입장에서 어떤 걸 좀 중점적으로 봐야 되느냐. 내가 남보다 좀 앞서 있는 어떤 타임 갭의 영역이 무엇이냐. 이젠 도메인이라는 표현도 무색할 정도로 그 도메인에서 절대 모델과 다른 사람들이 할 수 없는 어떤 암묵지의 영역, 그런 게 무엇이냐가 조합돼야 무언가를 만들 수 있는 세상이 되었다는 생각이 듭니다.”
OpenAI가 신규 투자를 발표. 이정도 규모의 투자를 단 세 군데의 펀딩만으로 모을 수 있구나.
“오늘 당사는 $730b 투자 전 기업가치로 $110b 규모의 신규 투자를 유치했음을 발표합니다. 여기에는 소프트뱅크 $30b, 엔비디아 $30b, 아마존 $50b가 포함됩니다. 또한 당사는 아마존과 전략적 파트너십을 체결하고 엔비디아와 차세대 추론용 컴퓨팅 인프라를 확보했습니다.
한편으로 $730b 기업가치는 앤트로픽의 Pre $350b와 거의 2배 밖에 차이가 나지 않는 것도 사실이다.
참고로 현재 OpenAI의 지표들을 살펴보면:
Codex WAU 200만명 / ChatGPT WAU 9억명
ARR $25b (cf 앤트로픽 ARR $19b)
최근들어서 앤트로픽의 기세가 무시무시해서 상대적으로 우려가 많아지는 OpenAI인데, 나름 자기 갈 길을 잘 걸어가고 있다고 생각한다. 최근에 출시한 GPT-5.4 모델도 훌륭한 것 같고 (강화학습 쪽에서는 OpenAI 역량이 강한 것 같다.)
Our agreement with the Department of War
앤트로픽과 미국 국방부가 대규모 감시와 자율 무기 개발 권한을 두고 충돌하였고, 결국 클로드가 국방부의 블랙리스트 명단에 드는 일이 발생했다.
결과적으로 이번 상황을 두고 OpenAI는 비즈니스를 진척시켰고, 앤트로픽은 기업의 철학을 강화시켰는데, 두 기업가의 색깔이 뚜렷하게 드러난 현상인 것 같다.
아래는 OpenAI의 공식 발표문:
“우리는 기밀 환경에 첨단 AI 시스템을 배포하는 것과 관련하여 펜타곤(미 국방부)과 합의에 도달했으며, 이 합의 조건을 모든 AI 기업에도 동일하게 제공해 줄 것을 요청했습니다. 우리는 이번 합의가 앤스로픽을 포함하여 과거에 있었던 그 어떤 기밀 AI 배포 합의보다 더 많은 가드레일(안전장치)을 갖추고 있다고 생각합니다.”
“우리는 국방부(DoW)와의 협력을 이끄는 세 가지 주요 ‘레드라인(한계선)’을 가지고 있으며, 이는 다른 여러 선도적인 AI 연구소들도 전반적으로 공유하는 원칙입니다.”
- 대규모 국내 감시를 위한 OpenAI 기술 사용 금지.
- 자율 무기 시스템을 지휘하기 위한 OpenAI 기술 사용 금지.
- 중대한 자동화된 의사결정(예: “사회 신용”과 같은 시스템)을 위한 OpenAI 기술 사용 금지.
우리의 합의 내용은 다음과 같습니다:
- 배포 아키텍처. 이는 클라우드 전용 배포로, 앞서 언급한 원칙 등을 포함하여 우리가 직접 운영하는 안전 스택이 적용됩니다. 우리는 국방부에 “가드레일이 해제된” 모델이나 안전 교육을 받지 않은 모델을 제공하지 않으며, 치명적인 자율 무기에 사용될 가능성이 있는 엣지 디바이스(edge devices)에 모델을 배포하지도 않습니다.
- 우리의 배포 아키텍처를 통해 우리는 분류기(classifier) 실행 및 업데이트를 포함하여 이러한 레드라인이 지켜지고 있는지 독립적으로 검증할 수 있습니다.”
계약 내용. 관련된 조항은 다음과 같습니다:
국방부(Department of War)는 적용 가능한 법률, 운영 요구 사항, 그리고 확고히 자리 잡은 안전 및 감독 프로토콜에 부합하는 모든 합법적인 목적을 위해 AI 시스템을 사용할 수 있다. AI 시스템은 법률, 규정 또는 부처 정책이 인간의 통제를 요구하는 어떠한 경우에도 자율 무기를 독립적으로 지휘하는 데 사용되지 않으며, 동일한 권한 하에 인간 의사결정자의 승인이 필요한 다른 중대한 의사결정을 대신하는 데에도 사용되지 않는다. 국방부 지침 3000.09(2023년 1월 25일 자)에 따라, 자율 및 반자율 시스템에서 AI를 사용할 때는 배포 전 실제 환경에서 의도한 대로 작동하는지 확인하기 위해 엄격한 검증, 확인 및 테스트를 거쳐야 한다.
정보 활동의 경우, 개인 정보의 취급은 수정헌법 제4조, 1947년 국가안보법, 1978년 해외정보감시법, 행정명령 12333호 및 명확한 해외 정보 목적을 요구하는 해당 국방부 지침을 준수해야 한다. AI 시스템은 이러한 권한과 일치하게 미국인의 개인 정보를 무제한으로 모니터링하는 데 사용되어서는 안 된다. 또한 이 시스템은 민병대 소집법(Posse Comitatus Act) 및 기타 해당 법률에서 허용하는 경우를 제외하고는 국내 법 집행 활동에 사용되어서는 안 된다.
AI 전문가 참여. 우리는 정부를 지원하기 위해 보안 인가를 받은 OpenAI 전진 배치(forward-deployed) 엔지니어들을 파견할 것이며, 보안 인가를 받은 안전 및 정렬(alignment) 연구원들이 이 과정에 지속적으로 개입할 것입니다.
Q. 앤스로픽은 합의에 도달하지 못했는데 어떻게 여러분은 도달할 수 있었나요? 앤스로픽이 거부한 계약에 서명한 것인가요?
우리가 아는 바에 따르면, 우리의 계약은 앤스로픽의 초기 계약을 포함하여 이전의 합의들보다 더 나은 보장과 더욱 책임감 있는 안전장치를 제공한다고 믿습니다. 배포가 (엣지가 아닌) 클라우드 전용으로 제한되고, 안전 스택이 우리가 생각하는 최선의 방식으로 작동하며, 보안 인가를 받은 OpenAI 인력이 과정에 계속 참여하기 때문에, 이 계약에서는 우리의 레드라인이 훨씬 더 잘 통제되고 집행될 수 있다고 생각합니다.
우리는 앤스로픽이 왜 합의에 도달하지 못했는지 알 수 없으며, 그들과 더 많은 연구소들이 이 조건을 고려해 주기를 바랍니다.
Q. 앤스로픽이 “공급망 위험(supply chain risk)”으로 지정되어야 한다고 생각하나요?
아닙니다. 우리는 이 문제에 대해 정부에 우리의 입장을 분명히 밝혔습니다.
Q. 이 계약을 통해 국방부가 OpenAI 모델을 사용하여 자율 무기를 구동할 수 있게 되나요?
아닙니다. 우리의 안전 스택, 클라우드 전용 배포, 계약서 문구, 그리고 기존의 법률, 규정 및 정책을 바탕으로 우리는 그런 일이 일어날 수 없다고 확신합니다. 또한 추가적인 보장을 위해 OpenAI 인력을 지속적으로 개입시킬 것입니다.
Full interview: Anthropic CEO responds to Trump order, Pentagon clash
이번 사건은 다가오는 AI 시대에 필연적으로 부딪힐 수밖에 없는 가치관과 통제권의 충돌 상황을 그대로 보여준 것 같은데, 앞으로 사회에서 이러한 류의 논의를 많이 접하게 되지 않을까.
아래는 다리오 아모데이의 입장:
우리는 국방부(Department of War)에 우리가 모든 사용 사례에 동의한다고 말했습니다. 기본적으로 그들이 원하시는 사용 사례의 98%나 99%에 동의하지만, 우리가 우려하는 두 가지는 예외입니다. 첫 번째는 국내 대중 감시입니다. 이 부분에서 우리는 AI로 인해 이전에는 불가능했던 일들이 가능해질 수 있다는 점을 우려하고 있습니다.
이에 대한 예시로는, 민간 기업이 수집한 데이터를 정부가 구매하여 AI를 통해 대규모로 분석하는 것 같은 일이 있습니다. 사실 그것이 불법은 아닙니다. 단지 AI 시대 이전에는 쓸모가 없었을 뿐이죠. 그래서 이렇듯 국내 대중 감시가 법을 앞서가고 있는 상황이 벌어지고 있습니다. 기술이 너무 빨리 발전해서 법과 보조가 맞지 않는 것이죠.
두 번째 경우는 완전 자율 무기입니다. 우크라이나에서 사용되거나 오늘날 대만에서 잠재적으로 사용될 수 있는 부분 자율 무기를 말하는 것이 아닙니다. 이것은 인간의 개입 없이 발사되는 무기를 만들겠다는 아이디어입니다.
우리는 그것들에 대해 몇 가지 우려를 가지고 있습니다. 오늘날의 AI 시스템은 완전 자율 무기를 만들 만큼 결코 신뢰할 수 있는 수준이 아닙니다. AI 모델을 다뤄본 사람이라면 누구나 순수하게 기술적인 측면에서 우리가 아직 해결하지 못한 기본적인 예측 불가능성이 있다는 것을 이해합니다. 그리고 감독의 문제도 있습니다. 인간의 감독 없이 작전을 수행할 수 있고, 누구를 표적으로 삼고 누구를 쏠 것인지 결정할 인간 군인이 없는 거대한 드론이나 로봇 군대가 있다면, 그것은 우려를 낳습니다. 우리는 그것이 어떻게 감독되어야 하는지에 대한 대화를 나눠야 하는데, 아직 그런 대화를 나누지 못했습니다.
Q. 펜타곤은 이 두 가지 제한 사항에 원칙적으로 동의했으며 거래를 성사시키고 싶었다고 우리에게 말했습니다. 왜 합의에 도달하지 못한 겁니까?
어느 시점에서 그들은 표면적으로는 우리의 조건을 충족하는 것처럼 보이는 문구를 보냈지만, “펜타곤이 적절하다고 판단하는 경우”라거나 “법에 부합하는 모든 것을 하기 위해” 같은 온갖 문구가 포함되어 있었습니다. 그래서 사실상 어떤 의미 있는 양보도 하지 않은 것이나 다름없었습니다. 그리고 그 이후의 과정들도 의미 있는 양보가 아니었습니다.
우리는 처음부터 합의를 원했습니다. 펜타곤의 입장을 이해하고 싶으시다면, 하루 전 펜타곤 대변인 숀 파넬(Sean Parnell)이 트윗을 통해 그들의 입장을 거듭 밝혔습니다. ‘우리는 합법적인 모든 사용만을 허용한다’는 내용이었고, 이는 그들이 우리에게 조건을 보냈을 때와 같았습니다. 그러니까, 그들은 양보하지 않았고, 그들은 어떤 의미 있는 방식으로도 우리의 예외 사항에 동의하지 않았습니다.
Q. 대통령은 오늘 이 상황에 대해 “앤스로픽을 지칭하는 그들의 이기심이 미국인들의 생명을 위험에 빠뜨리고, 우리 군대를 위험에 처하게 하며, 우리의 국가 안보를 위협하고 있다”고 포스팅했습니다. 어떻게 생각하십니까?
어제 발표한 성명과 오늘 발표한 성명에서도 밝혔듯이, 우리는 국방부나 심지어 트럼프 행정부가 우리를 상대로 이런 전례 없는 조치를 취하더라도, 보통 외국의 적들에게나 사용되는 이런 종류의 공급망 지정을 하더라도, 아시다시피, 그들이 이런 극단적인 조치를 취하더라도 국방부를 지원하기 위해 할 수 있는 모든 것을 하겠다고 말했습니다. 우리가 원하지 않는 일들을 하려는 의향이 있는 경쟁사를 도입하고 우리를 퇴출시킬 때까지 필요한 시간 동안 기술을 제공하겠다고 말이죠.
우리는 연속성을 제안했습니다. 사실 저는 이 상황이 매우 우려스럽습니다. 서비스 중단 같은 상황에 대해 깊이 걱정하고 있으며, 우리가 공급망 위험으로 지정되었을 때 정확히 그런 일이 일어나고 있습니다, 그렇죠? 우리가 공급망 위험으로 지정되면, 그들은 “당신들은 우리의 모든 시스템에서 나가야 한다”고 말합니다. 현장에 있는 현역 군 장교들과 이야기를 나눠봤는데, 그들은 이것이 필수적이라고 말합니다.
이것이 없으면 그들은 6개월, 12개월, 어쩌면 그 이상 뒤처지게 될 것입니다. 그래서 우리가 합의를 도출하려고 그렇게 열심히 노력한 것입니다. 하지만 거듭 말씀드리지만, 3일간의 최후통첩, 우리를 공급망 위험으로 지정하겠다는 위협, 이 모든 일정은 우리가 아니라 국방부가 주도한 것입니다. 우리는 연속성을 제공하려고 노력하고 있습니다.
우리는 서비스를 제공하려고 노력하고 있습니다. 우리는 여기서 합의에 도달하려고 노력하고 있습니다.
Q. 기본적인 원칙이라는 이름 아래, 왜 미국인들이 연방 정부 대신 민간 기업의 CEO인 당신이 이런 결정을 내리는 것을 신뢰해야 합니까?
거기에 대해서는 두 가지 대답을 드릴 수 있겠네요. 첫째, 아시다시피, 우리는 민간 기업입니다, 그렇죠? 우리는 우리가 원하는 것은 무엇이든 팔거나 팔지 않기로 결정할 수 있습니다. 다른 제공업체들도 있습니다. 만약 국방부나 정부가 우리가 제공하는 서비스나 방식을 마음에 들어 하지 않는다면 다른 계약업체를 쓰면 됩니다. 이것이 정상적인 처리 방식이었을 겁니다. 그냥 “당신들의 의견에 동의하지 않습니다. 우리는 앤스로픽과 일하고 싶지 않습니다. 우리의 원칙은 당신들의 원칙과 맞지 않습니다. 우리는 다른 모델 중 하나를 선택하겠습니다.”라고 했다면 저는 동의하지 않았겠지만 존중했을 것입니다.
하지만 그들은 이를 국방부(DO)를 넘어선 다른 정부 부처에까지 확대했고 국방부를 넘어서 징벌적으로 우리의 계약을 취소하려 했습니다. 그리고 그들은 이 공급망 지정이라는 것을 했는데, 이는 기본적으로 당신이 군사 계약을 맺고 있는 다른 민간 기업이라면 군사 계약과 관련된 방식으로 앤스로픽을 사용할 수 없다는 뜻입니다. 즉 그들은 민간 기업의 행동 영역까지 개입하고 있으며, 이를 징벌적 목적 외에 다른 방식으로 해석하기는 매우 어렵습니다.
우리가 알기로 공급망 지정이 미국 기업에 적용된 적은 없습니다. 이는 오직, 아시다시피, 러시아 정부와의 연관성이 의심되는 러시아 사이버 보안 기업인 카스퍼스키 랩스(Kaspersky Labs) 같은 적성국 기업들이나, 중국 칩 공급업체들을 그들과 한데 묶어서 적용되었을 뿐입니다. 우리가 미국의 국가 안보를 위해 해온 일들을 생각하면 이것은 매우 징벌적이고 부적절하게 느껴집니다.
Anthropic and Alignment - Stratechery
앤트로픽(특히 다모데이)의 이번 움직임이 멋지다고는 생각하지만, 합리적인 행동인지는 한번 질문해볼 필요가 있다.
이게 정답이 있는 문제는 아니지만, 민심이 조금 앤트로픽 쪽으로 치우져진 느낌도 없지 않아 있어서 나는 일부러 반대쪽 입장에서 생각을 많이 해보는 중이다. 아래는 벤 톰슨의 코멘트.
“제가 아모데이와 앤스로픽에 대해 가장 우려하는 점은, 모든 권력을 가진 단 한 명의 승자가 되는 데만 집착한 채 세상의 다른 사람들이 그 상황에 어떻게 반응할지에 대한 고려가 철저히 빠져 있다는 것입니다. 직설적으로 말해서, 세상에는 다른 사람들도 존재하며 그들은 총과 미사일, 심지어 핵무기를 가지고 있습니다. 여전히 ‘힘이 곧 정의’인 세상에서, 저는 이 사실을 지속적으로 망각하는 듯한 사람이나 기업에 인류의 미래를 넘겨주고 싶지 않습니다.”
“저는 AI의 감시 능력에 대해 극도의 불편함을 느낍니다. 과거 우리가 안전장치라고 믿었던 많은 것들이 사실은 단순히 ‘기술적 마찰(마음대로 하기 힘든 번거로움)’ 덕분에 유지되었던 경우가 많습니다. 컴퓨터와 인터넷을 뛰어넘어, AI는 이 ‘마찰’을 완벽하게 녹여버리는 용해제입니다. 따라서 이 특정 지점에 대한 앤스로픽의 우려가 많은 사람들의 공감을 얻는 이유를 백번 이해합니다.”
“하지만 이러한 새로운 현실에 대처하는 방법은 새로운 법률을 제정하고 책임 있는 정부의 감독을 강화하는 것이어야 합니다. 선출되지 않은 일개 기업의 경영진이 이 강력한 능력의 사용 방법과 장소를 결정하도록 요구하고 환호하는 것은 훨씬 더 전제적이고 위험한 미래로 가는 지름길입니다.”
“그 사이 우리의 적국들은 지체 없이 자율 전투 능력을 개발할 것입니다. 미국이 국제법의 최종적인 심판자이자 근원지로 남으려면 우리 역시 이 방향으로 나아갈 수밖에 없습니다. 그리고 제가 말하는 ‘미국’이란 샌프란시스코의 한 CEO가 아니라 민주적으로 선출된 의회와 대통령을 의미합니다. 총을 든 자들은 민간 기업이 자신들을 통제하는 것을 결코 용납하지 않을 것입니다. 앤스로픽은 이 현실을 직시하고 거기에 스스로를 맞춰야만 합니다.”
How AI Is Turbocharging the War in Iran - WSJ
한편으로는 이번 이란 전쟁이 AI의 중요성을 보여주고 있다.
국방부 입장에서는 안그래도 AI가 없어서는 안될 상황인데, 앤트로픽이 저렇게 나오니까 극단적으로 과하게 반응한 것 같기도 하고…
정보 분석: 방대한 감청 자료, 영상, 레이더 이미지를 빠르게 분석해 표적을 식별. 인간은 수집된 정보의 최대 4%만 검토할 수 있는데, AI가 이 병목을 해소. 특정 차량이나 항공기 기종을 자동 식별하거나, 감청 대화 요약도 가능
표적 선정 및 우선순위 결정: AI가 디지털 워게임과 시뮬레이션을 수백만 회 반복 실행해, 목표 달성 가능성이 높은 행동 방침을 도출. ‘병원 인근 미사일 발사대’처럼 조건부 검색도 가능
임무 계획 수립: 기존에는 수 주가 걸리던 작전 계획을 수일 내로 단축. 표적이 변경되면 항공기, 무기, 승무원 편성, 연료 소비 등 연쇄적으로 영향받는 요소들을 즉각 재계산
전투 피해 평가: 공격 후 시각 정보, 레이더, 열 신호 등 다양한 데이터를 ‘센서 융합’으로 통합 분석해 타격 성공 여부를 빠르게 판단하고, 이를 바탕으로 후속 표적 목록을 정교화
재고, 보급품 관리: 탄약, 부품 등 보급품 관리와 각 목표에 최적의 무기를 매칭
(출처: 카이에 텔레그램 https://t.me/cahier_de_market/8845)
GPT-5.2, 이론물리학 새 공식 도출...글루온 입자 상호작용 메커니즘 규명
GPT-5.2 derives a new result in theoretical physics
전쟁 외에도 AI는 세상의 비밀을 풀어내는 단계까지 왔으며
“이 연구의 핵심적인 측면은 방법론에 관한 것입니다. 프리프린트(preprint)의 식 (39)에 해당하는 최종 공식은 GPT‑5.2 Pro가 처음으로 추측해 낸 것입니다. 인간 저자들은 정수 에 대하여 일 때까지의 진폭(amplitudes)을 수작업으로 계산하여 식 (29)--(32)와 같은 매우 복잡한 수식을 도출했습니다. 이는 이 커짐에 따라 복잡도가 초지수적(superexponentially)으로 증가하는 “파인만 다이어그램 전개(Feynman diagram expansion)”에 해당합니다. GPT‑5.2 Pro는 이러한 수식들의 복잡도를 대폭 낮추어, 식 (35)--(38)과 같은 훨씬 더 간단한 형태를 제시했습니다. 이러한 기본 사례들을 바탕으로 GPT‑5.2 Pro는 패턴을 발견하고 모든 에 대해 성립하는 공식을 제안할 수 있었습니다.”
“이후 내부 스캐폴딩(scaffolded) 버전의 GPT‑5.2가 약 12시간 동안 해당 문제를 추론한 끝에 동일한 공식을 도출해 냈으며, 그 타당성에 대한 형식적 증명(formal proof)까지 생성해 냈습니다. 이 공식은 추후 해석적 검증을 거쳐, 더 작은 구성 요소로부터 다입자 트리 진폭(multi-particle tree amplitudes)을 구축하는 표준적인 단계별 방법인 ‘베렌즈-길레(Berends-Giele) 점화식’을 만족함이 확인되었습니다. 또한 입자가 ‘소프트(soft)’ 상태가 될 때(에너지가 0에 가까워질 때) 진폭의 거동을 제약하는 ‘소프트 정리(soft theorem)’와도 일치함이 확인되었습니다.”
“GPT‑5.2의 도움으로 이러한 진폭 계산은 이미 글루온(gluons)에서 중력자(gravitons)로 확장되었으며, 다른 일반화 작업들도 진행 중입니다. 이러한 AI 협력 연구 결과들과 여타 많은 성과들은 별도의 지면을 통해 보고될 예정입니다.”
The third era of AI software development - Michael Truell
이제는 단일 에이전트를 넘어 멀티 에이전트의 시대도 찾아오기 바로 직전이다.
실제로 코딩은 인간이 지시를 내리는 과정이 남아있던 에이전트를 넘어 FSD스러운 멀티 에이전트로 바뀌는 과정에 있다.
“몇 년 전 저희가 Cursor를 처음 만들기 시작했을 때만 해도, 대부분의 코드는 키보드를 한 번에 하나씩 두드려가며 작성되었습니다. 탭(Tab) 자동완성은 이를 변화시켰고, AI 기반 코딩의 첫 번째 시대를 열었습니다.”
“그 후 에이전트가 등장했고, 개발자들은 동기식 프롬프트-응답 루프를 통해 에이전트에게 지시를 내리는 방식으로 전환했습니다. 이것이 두 번째 시대였습니다. 그리고 이제 세 번째 시대가 도래하고 있습니다. 이 시대는 인간의 지시를 덜 받으면서도 더 긴 시간 동안 독립적으로 더 큰 작업을 처리할 수 있는 에이전트로 정의됩니다.”
“결과적으로 Cursor는 더 이상 ‘코드를 작성하는 것’만을 주된 목적으로 하지 않습니다. 개발자들이 소프트웨어를 만들어내는 ‘공장’을 구축하도록 돕는 것에 가깝습니다. 이 공장은 개발자가 초기 방향을 제시하고, 독립적으로 작업할 수 있는 도구를 제공하며, 결과물을 검토하는 등 팀원처럼 상호작용하는 수많은 에이전트 무리로 구성됩니다.”
“Cursor의 많은 팀원들은 이미 이러한 방식으로 일하고 있습니다. 우리가 병합(Merge)하는 PR(Pull Request)의 3분의 1 이상이 이제 클라우드 상의 자체 컴퓨터에서 실행되는 에이전트에 의해 생성됩니다. 지금으로부터 1년 후에는 개발 작업의 대부분이 이러한 종류의 에이전트에 의해 이루어질 것으로 생각합니다.”
Towards self-driving codebases · Cursor
커서가 자율적으로 동작하는 멀티 에이전트를 만들어낸 과정.
인간이 계속해서 발전시켜온 조직에 대한 시스템을 이제는 AI 에이전트에게 전수해주는 과정이 시작된 것 같다. 대학에서 배운 조직행동론이 떠오르기도...
“최종 설계는 우리의 모든 배움을 통합했습니다.”
루트 기획자(Root Planner): 사용자 지시의 전체 범위를 소유합니다. 현재 상태를 이해하고 목표를 향해 나아갈 구체적이고 타겟팅된 작업을 전달하는 책임이 있습니다. 직접 코딩하지 않으며, 자신의 작업이 누구에게 픽업되는지 알지 못합니다.
하위 기획자(Subplanners): 기획자가 자신의 범위를 세분화할 수 있다고 판단하면, 위임된 좁은 영역(Slice)을 완전히 소유하는 하위 기획자를 생성합니다. 이들은 루트 기획자와 비슷하게 해당 영역에 대해 완전한 소유권을 갖습니다. 이는 재귀적(Recursive)입니다.
작업자(Workers): 작업을 픽업하고 완료까지 책임지는 유일한 주체입니다. 이들은 더 큰 시스템을 인지하지 못하며 다른 기획자나 작업자와 소통하지 않습니다. 자신만의 저장소(Repo) 사본에서 작업하며, 완료되면 시스템이 요청한 기획자에게 제출할 단일 핸드오프(Handoff)를 작성합니다.
“흥미롭게도, 이는 오늘날 일부 소프트웨어 팀이 운영되는 방식과 유사합니다.”
하위 기획자는 작업자를 빠르게 부채꼴로 확장(Fan out)하여 처리량을 늘리는 동시에, 에이전트가 전체 시스템을 완전히 소유하고 책임지도록 합니다. 이는 단일 기획자가 압도되어 터널 시야(Tunnel vision)에 빠질 수 있는 대형 프로젝트와 작업에도 도움이 되었습니다.
핸드오프에는 완료된 작업뿐만 아니라 중요한 메모, 우려 사항, 편차, 발견 사항, 생각, 피드백이 포함됩니다. 기획자는 이를 후속 메시지로 받습니다. 이를 통해 시스템은 지속적으로 움직이는 상태를 유지합니다. 기획자가 “완료”되었더라도 업데이트를 계속 받고, 최신 저장소를 가져오며, 계속해서 계획하고 후속 결정을 내릴 수 있습니다.
모든 에이전트는 이 메커니즘을 가지고 있어, 시스템이 전역 동기화나 상호 대화(Cross-talk)의 오버헤드 없이 정보를 체인을 따라 상위 소유자에게 전파하며 믿을 수 없을 정도로 동적이고 자기 수렴적(Self-converging)이게 만듭니다.
“이 멀티 에이전트 시스템에 주어지는 지시 사항(Instructions)은 매우 중요했습니다.”
처음에는 이것을 주요 목표로 삼지 않고, 안정적이고 효과적인 하네스를 목표로 했습니다. 하지만 지시 사항의 중요성은 금방 명백해졌습니다. 우리는 본질적으로 일반적인 코딩 에이전트와 상호작용하고 있었지만, 훨씬 더 많은 시간과 연산을 사용하고 있었습니다. 이는 최적화되지 않고 불분명한 지시 사항을 포함한 모든 것을 증폭시킵니다.
초기 지시 사항에 더 많은 시간을 할애하는 것이 합리적입니다. 결국 에이전트는 여전히 에이전트입니다. 당신의 지시를 엄격히 따르고, 그 경로로 가며, 지시가 나쁘더라도 변경하거나 무시하지 않도록 훈련받았습니다.
아키텍처와 지시 사항은 중요합니다. 에이전트는 엄청난 엔지니어링 기술을 가지고 있지만 좋든 나쁘든 지시를 끝까지 따를 것입니다. 지나치게 좁은 지표와 구조 없는 자유 사이의 균형을 찾는 것은 까다로웠으며, 무엇이 명백하고 무엇이 명시적 언급이 필요한지 아는 것도 마찬가지였습니다.
이 모든 것은 의도를 도출하고, 명시하고, 이해하는 것의 중요성을 시사하며, 이는 이 규모에서 더욱 중요해집니다. 조종 가능성(Steerability)과 관측 가능성은 계속 탐구해야 할 흥미로운 연구 분야가 될 것입니다.
Dario Amodei — “We are near the end of the exponential”
드와캐시 파텔이 인터뷰한 다리오 아모데이. 역시나 AI는 멈출 기미가 보이지 않는다.
“우리는 사전 훈련에 대해 긍정적으로 생각합니다. 계속해서 이득을 주고 있으니까요. 달라진 점은 이제 RL(강화학습)에서도 똑같은 현상을 목격하고 있다는 것입니다. 우리는 사전 훈련 단계를 거친 뒤 그 위에 RL 단계를 봅니다. RL의 경우도 사실 똑같습니다. 다른 회사들도 발표 자료에서 “우리는 모델을 수학 경시대회(AIME 등)로 훈련시켰고, 모델이 얼마나 잘하는지는 훈련 시간에 대해 로그 선형(log-linear) 관계를 보인다”라고 밝히고 있습니다. 단순히 수학 경시대회뿐만이 아닙니다. 매우 다양한 RL 작업에서 그렇습니다. 우리는 사전 훈련에서 보았던 것과 똑같은 스케일링을 RL에서도 보고 있습니다.”
“당신이 표현한 대로 “10년 안에 ‘데이터센터 안의 천재들의 나라(country of geniuses in a data center)’에 도달할 것인가”라는 기본 가설에 대해, 저는 90% 정도 확신합니다. (~) 10년 타임라인에 대해서 저는 90% 확신하며, 이는 사람이 가질 수 있는 거의 최대한의 확신입니다. 2035년까지 이 일이 일어나지 않을 것이라고 말하는 건 미친 소리라고 생각합니다. 제정신인 세상이라면 그건 주류 의견에서 벗어난 것일 겁니다.”
“우리는 이미 검증되는 것에서 검증되지 않는 것으로의 상당한 일반화를 보고 있습니다. 이미 보고 있어요.”
“지속적 학습(continual learning), 즉 단일 모델이 업무 중에 학습한다는 아이디어를 우리는 연구하고 있습니다. 향후 1~2년 안에 우리도 그것을 해결할 가능성이 큽니다. 다시 말하지만, 저는 그것 없이도 대부분 도달할 수 있다고 생각합니다. 연간 수조 달러 시장, 어쩌면 제가 “기술의 사춘기”에서 쓴 모든 국가 안보적 함의와 안전 함의가 그것 없이도 일어날 수 있습니다. 하지만 우리, 그리고 다른 이들도 continual learning를 연구하고 있다고 상상합니다. 우리가 1~2년 안에 그곳에 도달할 가능성이 큽니다.”
“여러 아이디어가 있습니다. 자세히 다 설명하진 않겠지만, 하나는 단순히 컨텍스트를 더 길게 만드는 것입니다. 더 긴 컨텍스트가 작동하는 것을 막는 건 없습니다. 단지 더 긴 컨텍스트에서 훈련하고 추론 시 그것을 서빙하는 법을 배워야 할 뿐입니다. 둘 다 우리가 작업하고 있는 엔지니어링 문제이며, 다른 이들도 작업하고 있을 것이라 가정합니다.”
“우리는 엔터프라이즈(기업용) 비즈니스입니다. 따라서 우리는 매출에 더 의존할 수 있습니다. 소비자 시장보다 변덕이 덜하죠. 우리는 더 나은 마진을 가지고 있는데, 이건 너무 많이 사는 것과 너무 적게 사는 것 사이의 완충제 역할을 합니다. 저는 우리가 꽤 강력한 상승세(upside)의 세상들을 포착할 수 있는 양만큼 구매했다고 생각합니다. 연 10배 성장을 전부 포착하진 못하겠지만요. 우리가 재정적 어려움에 처하려면 상황이 꽤 나쁘게 돌아가야 할 겁니다. 그래서 우리는 신중하게 생각했고 그런 균형을 잡았습니다. 이것이 제가 우리가 책임감 있게 행동하고 있다고 말할 때 의미하는 바입니다.”
“업계 전체에 대해 이야기하자면, 올해 업계가 구축하고 있는 컴퓨팅 양은 아마 10~15 기가와트 정도일 겁니다. 매년 대략 3배씩 증가합니다. 그러니 내년은 30~40 기가와트입니다. 2028년은 100 기가와트가 될 수 있습니다. 2029년은 300 기가와트 정도가 될 수 있습니다. 머릿속으로 계산 중인데, 1 기가와트당 비용은 아마 100억 달러, 연간 100억~150억 달러 수준일 겁니다. 이걸 다 합치면 당신이 설명한 것과 거의 비슷해집니다. 정확히 그걸 얻게 되는 거죠. 2028년이나 2029년이면 연간 수조 달러 규모가 됩니다. 당신이 예측한 것과 정확히 일치합니다.”
“2030년 이전에 매출이 수조 달러가 되지 않는 상황은 저로서는 상상하기 힘듭니다. 그럴듯한 세상을 구성해 볼 수는 있습니다. 아마 3년이 걸리겠죠. 그게 제가 생각하기에 그럴듯한 범위의 끝일 겁니다. 예를 들어 2028년에 우리가 진짜 “데이터 센터 안의 천재들의 나라”를 얻습니다. 매출은 2028년까지 수천억 달러 초반대로 가고, 그러고 나서 천재들의 나라가 그것을 수조 달러로 가속화합니다. 우리는 기본적으로 확산의 느린 쪽 끝에 있는 겁니다. 수조 달러에 도달하는 데 2년이 걸립니다. 그게 2030년까지 걸리는 세상일 겁니다. 저는 기술적 지수 함수와 확산 지수 함수를 결합하더라도 2030년 이전에 도달할 것이라고 생각합니다.”
“다시 말하지만, 지금 당장의 총마진은 매우 긍정적입니다. 무슨 일이 일어나고 있냐면 두 가지가 결합되어 있습니다. 하나는 우리가 여전히 컴퓨팅의 지수적 확장 단계에 있다는 것입니다. 모델 하나가 훈련됩니다. 작년에 10억 달러가 든 모델이 훈련되었다고 칩시다. 올해 그 모델은 40억 달러의 매출을 올렸고 추론 비용으로 10억 달러가 들었습니다. 다시 정형화된 숫자를 쓰지만, 이건 75%의 총마진과 25%의 비용이 되는 셈입니다. 그래서 그 모델 전체로는 20억 달러를 법니다. 하지만 동시에, 우리는 다음 모델을 훈련하는 데 100억 달러를 쓰고 있습니다. 지수적 확장이 있으니까요. 그래서 회사는 돈을 잃습니다. 각 모델은 돈을 벌지만, 회사는 돈을 잃습니다.”
“클라우드는 매우 차별화되지 않았습니다(undifferentiated). 반대로 모델들은 클라우드보다 더 차별화되어 있습니다. 누구나 클로드는 GPT가 잘하는 것과는 다른 걸 잘하고, 제미나이가 잘하는 것과는 다른 걸 잘한다는 걸 압니다. 단순히 클로드는 코딩을 잘하고, GPT는 수학과 추론을 잘한다는 정도가 아닙니다. 그보다 더 미묘합니다. 모델들은 서로 다른 유형의 코딩을 잘합니다. 모델들은 서로 다른 스타일을 가지고 있습니다. 저는 이것들이 사실 서로 꽤 다르다고 생각하며, 그래서 클라우드에서 보는 것보다 더 많은 차별화를 기대합니다.”
“저는 API 비즈니스 모델이 다른 모델들과 공존하겠지만, 항상 존재할 것이라고 예측합니다. 왜냐하면 항상 1,000명의 다른 사람들이 모델을 다른 방식으로 실험해 볼 필요가 있을 테니까요. 그중 100개가 스타트업이 되고 그중 10개가 크고 성공적인 스타트업이 됩니다. 2~3개는 특정 세대의 모델을 사람들이 사용하는 주된 방식이 되죠.”
“모델이 출력하는 모든 토큰이 같은 가치를 지니지는 않습니다. 누군가 전화해서 “내 맥(Mac)이 안 돼요”라고 했을 때 모델이 “재부팅하세요”라고 출력하는 토큰의 가치를 생각해 보세요. 그 사람은 처음 들었겠지만 모델은 그 말을 1,000만 번 했습니다. 아마 그건 1달러나 몇 센트 정도의 가치겠죠. 반면 모델이 제약 회사 중 한 곳에 가서 “아, 당신들이 개발 중인 이 분자 말인데요, 분자 저쪽 끝에 있는 방향족 고리를 이쪽 끝으로 옮겨 보세요. 그렇게 하면 놀라운 일이 일어날 겁니다”라고 말한다면요. 그 토큰들은 수천만 달러의 가치가 있을 수 있습니다.”
#하드웨어
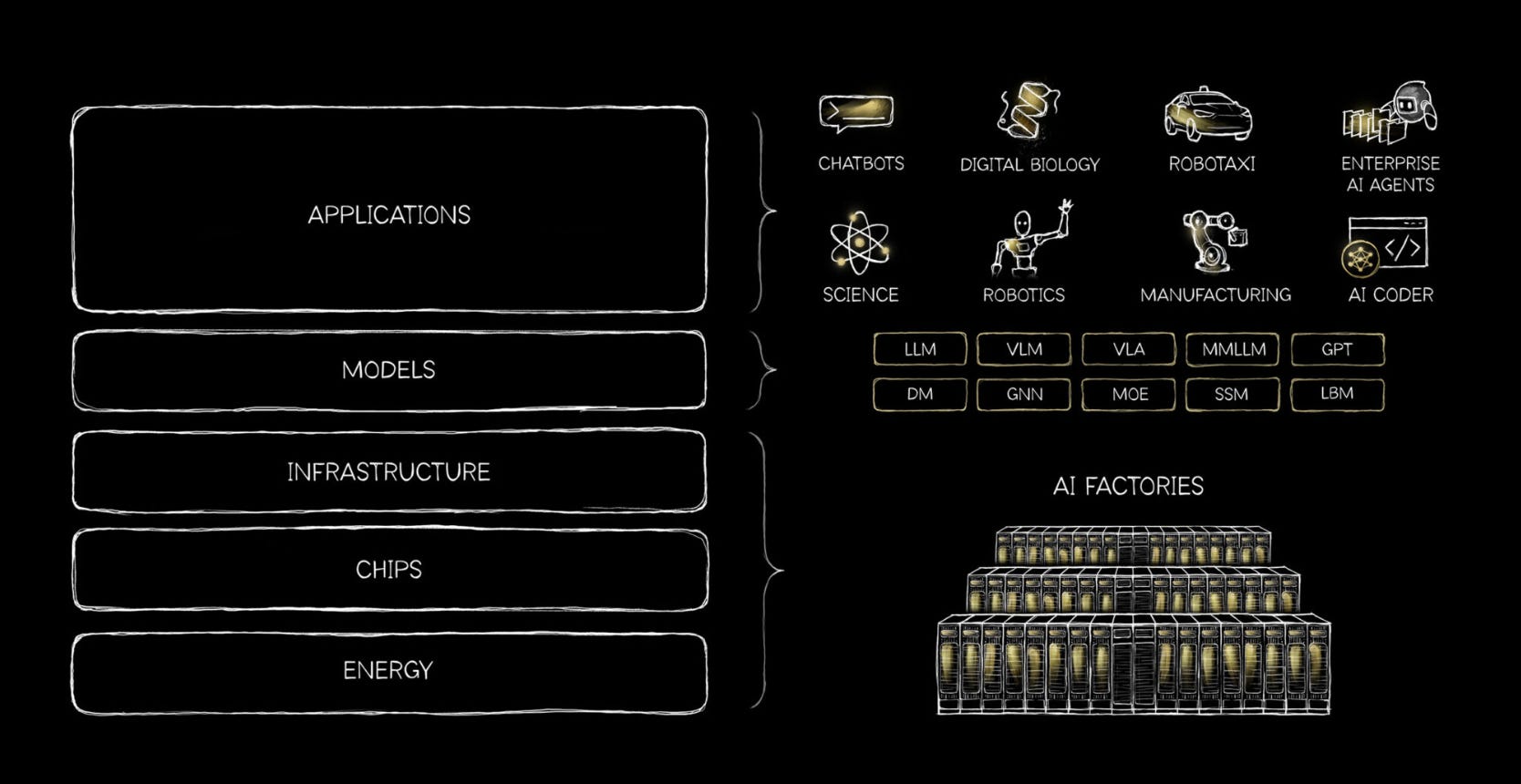
AI 구성 요소를 5계층으로 정리하면서, 거대한 인프라 투자의 당위성을 다시 한번 강조한 젠슨 황.
“AI를 필수적인 인프라로 바라볼 때, 그것이 시사하는 바는 명확해집니다.”
“AI는 트랜스포머 LLM에서 시작되지만, 그 의미는 훨씬 더 큽니다. 이는 에너지가 생산되고 소비되는 방식, 공장이 건설되는 방식, 업무가 조직되는 방식, 그리고 경제가 성장하는 방식을 재편하는 하나의 산업적 대전환입니다.”
“이제 지능이 실시간으로 생성되고 있기 때문에 AI 공장들이 세워지고 있습니다. 효율성이 지능의 확장 속도를 결정하기 때문에 반도체 칩이 재설계되고 있습니다. 에너지는 애초에 지능을 얼마나 많이 생산할 수 있는지 그 상한선을 설정하기 때문에 가장 핵심적인 요소가 됩니다. 애플리케이션들은 그 기반이 되는 모델들이 마침내 대규모로 유용하게 쓰일 수 있는 임계점을 넘었기 때문에 가속화되고 있습니다.”
“이 모든 계층은 서로를 강화합니다.”
“이것이 바로 AI 인프라 구축 규모가 그토록 거대한 이유입니다. 이것이 AI가 수많은 산업에 동시에 영향을 미치는 이유이며, 단일 국가나 특정 부문에만 국한되지 않는 이유입니다. 모든 기업이 AI를 사용할 것이며, 모든 국가가 이를 구축할 것입니다.”
“우리는 아직 초기 단계에 있습니다. 인프라의 많은 부분이 아직 존재하지 않으며, 인력의 상당수도 아직 교육받지 못했습니다. 많은 기회가 아직 실현되지 않은 상태입니다.”
“하지만 방향성만큼은 분명합니다. AI는 현대 세계의 근간이 되는 기반 인프라로 자리 잡고 있습니다. 그리고 우리가 지금 내리는 선택들—얼마나 빨리 구축하고, 얼마나 폭넓게 참여하며, 얼마나 책임감 있게 도입할 것인가—이 새로운 시대의 모습을 결정지을 것입니다.”
고객들의 부채조달을 동원한 대규모 capex지속가능성에 대한 질문에 대해 젠슨황의 대답 (엔비디아 실적발표):
저는 고객사들의 현금흐름이 증가할 것이라고 확신하며, 그 이유는 매우 단순합니다.
이제 에이전틱 AI의 변곡점을 확인했고, 전 세계 기업들에서 에이전트의 유용성이 입증되면서 그로 인해 엄청난 컴퓨팅 수요가 나타나고 있습니다. 이 새로운 AI의 세계에서는요. 컴퓨팅은 곧 매출입니다. 컴퓨팅이 없으면 토큰을 생성할 방법이 없습니다. 토큰이 없으면 매출을 늘릴 방법이 없습니다. 그래서 이 새로운 AI의 세계에서는 컴퓨팅이 곧 매출입니다. 그리고 저는 현시점에서 Codex와 Claude Code의 제품화된 활용, Claude Cowork를 둘러싼 기대감, 그리고 OpenClaw 및 그 엔터프라이즈 버전에 대한 엄청난 열의까지 감안하면, 이제 자사 도구와 플랫폼 위에서 에이전틱 시스템을 구축하고 있는 모든 엔터프라이즈 ISV들이 있다고 확신합니다. 저는 현시점에서 우리가 변곡점에 와 있다고 확신합니다.우리는 변곡점에 도달했고, 고객에게는 생산성을 높여주고 클라우드 서비스 제공업체에는 수익성이 있는 토큰을 만들어내고 있습니다. 그래서 이를 단순하게, 가장 단순한 논리로 생각해보면, 컴퓨팅은 과거에 컴퓨터에서 소프트웨어가 돌아가던 방식 자체를 바꿔놓았습니다. - 출처: 카이에 텔레그램
이전부터 나는 AI의 구동 레이어가 클라우드를 대체해서 로컬이 된다는 시나리오는 확률이 적다고 보았는데, 최근 메모리 가격 상승은 이에 대한 확률을 더욱 올려버렸다.
“콜라스 부스타만테(Nicolas Bustamante)는 AI 시대의 버티컬 소프트웨어) 전망에 대한 X 게시물에서 이것이 왜 위협적인지 설명했습니다: 인터페이스가 자연어 대화가 되면, 수년 동안 쌓아온 근육 기억(muscle memory)은 무가치해집니다. 연간 좌석당 2만 5천 달러를 정당화했던 전환 비용이 사라지는 것입니다. 많은 수직적 소프트웨어 기업에게 인터페이스는 가치의 대부분이었습니다. 기본 데이터는 라이선스 방식이거나 공개되었거나 혹은 반쯤 범용화된 상태였습니다. 프리미엄 가격을 정당화했던 것은 그 데이터 위에 구축된 워크플로우였습니다. 이제 그 시대는 끝났습니다.”
“부스타만테의 글은 채팅 인터페이스 이상의 내용을 담고 있지만, 저는 사용자 인터페이스에 대한 지적이 심오하다고 생각합니다. AI 사용자 인터페이스가 다르다는 점보다는, 많은 사용 사례에서 UI가 기본적으로 존재하지 않게 된다는 점이 중요합니다.”
“이는 AI의 다음 거대한 물결인 ‘에이전트’를 고려할 때 더욱 분명해집니다. 에이전트의 핵심은 당신을 위해 컴퓨터를 사용하는 것이 아니라, 특정 작업을 완수하는 것입니다. 요청과 결과 사이의 모든 과정은, 적어도 이론적으로는 사용자에게 보이지 않아야 합니다. 이것은 씬(thin) 클라이언트 개념을 절대적인 극단으로 가져간 것입니다. 챗봇에서 답변을 얻기 위해 로컬 연산이 필요 없는 수준을 넘어, 실제 업무를 수행하는 데에도 로컬 연산이 필요 없어지는 것입니다. 서버의 AI가 모든 것을 처리합니다.”
→
“물론 현재 작동하는 대부분의 에이전트 워크플로우는 정해진 ‘황금 경로(golden path)’를 따를 때는 잘 작동하지만, 더 복잡한 상황이나 예외적인 경우(edge cases)에는 비틀거립니다. 하지만 모델이 더 좋아지고 이를 실행하는 칩의 기능, 특히 메모리 측면이 향상됨에 따라 상황은 빠르게 변하고 있습니다. 추론(inference)에 있어서 메모리는 모델 가중치를 유지하는 것뿐만 아니라 당면한 작업에 대한 문맥(context)을 유지하는 데에도 중요합니다.”
“지금까지 중요한 메모리의 대부분은 GPU에 부착된 고대역폭 메모리(HBM)였지만, 미래의 아키텍처는 문맥을 플래시 스토리지로 오프로드할 것입니다. 동시에 에이전트 관리는 대량의 DRAM을 필요로 하는 CPU에 가장 적합합니다. 요약하자면, 우리가 가진 연산량과 그 연산 능력 모두 아직 충분하지 않습니다. 하지만 그 임계점을 넘어서면 수요는 훨씬 더 강력해질 것입니다.”
이러한 요인들의 결합은 씬 클라이언트 패러다임의 지배력을 더욱 강화할 것입니다:
첫째, 컴퓨팅이 아직 충분히 좋지 않다면, 워크로드는 컴퓨팅이 가장 좋은 곳, 즉 대규모 데이터 센터로 흘러갈 것입니다.
둘째, 더 큰 모델과 더 많은 문맥이 더 나은 결과를 만든다면, 워크로드는 사용 가능한 메모리가 가장 많은 곳으로 흘러갈 것입니다.
셋째, 이 수준의 컴퓨팅을 제공하는 비용을 고려할 때, 수백만 명의 사용자들 사이에서 그 비용을 나누는 것이 훨씬 더 경제적이며, 이는 높은 활용도를 보장하고 초기 비용에 대한 레버리지를 극대화합니다.
“물론 대규모 언어 모델(LLM)을 로컬에서 실행할 수도 있지만, 모델의 크기, 컨텍스트 창(context window)의 크기, 그리고 속도 면에서 제한이 있습니다. 반면, 우수한 컨텍스트 창과 더 빠른 속도를 갖춘 우수한 모델들은 컴퓨터 실험실에 갈 필요 없이 어디서나 인터넷에 연결하기만 하면 됩니다. 이러한 현실은 OpenClaw와 같은 놀라운 새로운 로컬 도구에도 적용됩니다. OpenClaw는 로컬에서 실행되는 오케스트레이션 계층이지만, 실제 AI 추론은 기본적으로 그리고 대부분의 사용자에게 있어 실제로는 클라우드의 모델에 의해 수행됩니다.”
“달리 말해, 로컬 추론이 경쟁력을 가지려면 ‘작지만 충분히 유능한 모델’, ‘컨텍스트 관리의 획기적 발전’, 그리고 결정적으로 ‘엄청나게 많은 메모리’의 조합이 필요합니다. 그리고 그중 가장 큰 문제는 바로 메모리일 가능성이 큽니다.”
Copilot Cowork, Anthropic’s Integration, Microsoft’s New Bundle
앤트로픽의 코워크는 로컬에서 작동하지만, 마이크로소프트는 이를 클라우드 환경 안으로 끌고왔다.
“로컬 컴퓨터와 파일은 보안의 허점이 될 수 있는 반면, 기업 IT 팀은 클라우드 환경에 무엇이 있는지, 누가 혹은 무엇이 접근 권한을 갖는지에 대해 훨씬 더 강력한 통제력을 가지며 모든 작업이 기록되기 때문입니다.”
“이는 사실 ‘씬 이즈 인(Thin is In, 씬 클라이언트 및 클라우드 중앙집중화)’ 테제를 뒷받침하는 또 다른 근거이기도 합니다. 만약 AI 채택이 하향식(top-down)으로 주도될 것이라는 주장을 수용한다면, 자연스럽게 AI 사용은 로컬 기기가 아닌 기업의 클라우드에 중앙 집중화될 것이라는 결론이 나옵니다.”
“한편으로 코워크는 앤스로픽만이 고유하게 제공할 수 있는 역량이기 때문에 마이크로소프트는 확실히 앤스로픽에 상당한 마진을 지불하고 있을 것입니다. 하지만 다른 한편으로 코워크를 워크 IQ 및 기업의 클라우드 환경에 전 세계적 규모로 통합할 수 있는 마이크로소프트의 능력은 앤스로픽이 수년 내에는 물론이고 앞으로도 결코 자체적으로 달성할 수 없는 거대한 규모입니다. 유통과 배포(Distribution)는 여전히 중요하며, 마이크로소프트는 이를 대규모로 활용하고 있습니다.”
Oracle Announces Fiscal Year 2026 Third Quarter Financial Results
마침 오늘자 오라클 실적발표 콜에서도 비슷한 이야기가 나오네.
“초기에는 많은 사람들이, 아마도 대부분의 고객이 자기들만의 대규모 언어모델을 아주 구체적으로 학습시키게 될 것이라고 생각했습니다. 저는 그것이 대체로 그렇지 않은 것으로 판명되었다고 생각합니다. 대신 지금 엄청나게 인기가 있고 점점 더 인기를 얻고 있는 것은 사람들이 최고의 모델들을 가져와서, 그것을 자기들의 프라이빗 데이터와 프라이빗한 방식으로 결합하기를 원한다는 점입니다.”
“우리는 그에 대한 많은 수요를 보고 있습니다. Mike가 앞서 말한 것처럼 우리가 이 AI 모델들을 애플리케이션 안에 내장하고 있다는 것이 하나의 유스케이스입니다. 하지만 당연히 불행히도 모든 것이 Oracle 애플리케이션 안에서 돌아가는 것은 아니고, 많은 커스텀 애플리케이션이 작성됩니다. 그래서 우리는 Oracle AI Database에 많은 기능을 추가했습니다. MCP 서버를 통해서든, 자연어를 SQL로 바꾸는 방식이든, 고객이 이런 모델들을 쉽게 활용할 수 있도록 연결을 쉽게 만들었습니다.”
“또한 우리는 AI Data Platform 제품도 갖고 있는데, 이는 정확히 이 문제를 해결하기 위한 것입니다. 여러분에게 많은 데이터가 있습니다. 그것은 애플리케이션 데이터일 수도 있고, 여러 데이터 레이크와 레이크하우스에 있는 커스텀 데이터일 수도 있으며, 구조화된 데이터베이스 안의 데이터일 수도 있습니다. 이 모든 것을 함께 사용하면, 여러 제공자로부터 최고의 모델들에 대한 접근성과 함께 애플리케이션을 빠르게 구축할 수 있는 에이전트 플랫폼을 얻게 됩니다.”
“그래서 스택 전반에서 우리는 그에 대한 많은 모멘텀을 보고 있습니다. 제가 준비된 발언에서 멀티클라우드 데이터베이스의 성장에 대해 이야기한 이유도 그것입니다.”
“우리가 보는 것은, 고객이 최신 AI를 활용하기 위해서는 우선 클라우드에 있어야 한다는 점이며, 여전히 클라우드에 있지 않은 데이터가 아주 많습니다. 따라서 고객들이 가장 중요한 프라이빗 데이터를 클라우드 환경으로 옮기는 속도가 빨라지고 있으며, 그렇게 해야 그 데이터를 가지고 최신 AI를 활용할 수 있게 됩니다.”
메모리 수요가 AI 시대에 폭발적으로 증가하는 이유 - Dongsoo Lee
메모리에 관하여 현직자의 이야기를 들어보시죠:
“최근의 Agentic AI는 이 구조를 다시 확장한다. 여러 에이전트가 협력하고, 역할을 분담하고, 장기간 상태를 유지하는 구조에서는 메모리의 의미가 완전히 달라진다.”
“대화 맥락, 중간 추론 결과, 도구 사용 기록, 에이전트 간 메시지가 모두 장기적으로 유지된다. KV cache는 단순한 버퍼가 아니라 협업을 위한 작업 기억이 된다.“
“에이전트 수가 늘어나면 메모리 사용량은 선형적으로 증가하지 않는다. 상태 공간이 겹치고, 상호 참조되며, 반복 저장되기 때문이다. 메모리는 협업 인프라가 된다.”
“지금 우리가 목격하는 변화의 핵심은 “메모리 사용량이 서비스 품질과 직접적으로 연결되는 최초의 대규모 산업 구조가 형성”되었다는 점이다.”
“더 큰 모델, 더 긴 맥락, 더 많은 에이전트는 모두 더 많은 메모리를 필요로 한다. 그리고 이는 곧 더 높은 문제 해결 능력으로 이어진다.”
“CPU 시대에는 캐시가 메모리를 가렸다. 스트리밍 시대에는 네트워크가 저장을 대체했다. AI 시대에는 메모리를 숨길 수 없다. 메모리는 이제 지능의 물리적 기반이며, 협업의 토대다.”
관련해서 낸드의 중요성이 급격히 중요해지고 있다.
“데이터센터 내 NVMe의 시대는 이미 왔다. 특히나 ICMS 같은 아키텍쳐가 일반화된다면 더욱이 NVMe SSD 수요를 급증시킬 수 있으리라 본다. 국내의 하이닉스, 삼성뿐만 아니라, NAND Vendor들에겐 이만한 호재가 없을 것이다. 이미 알려진 것처럼, 내년도 물량까지 수주가 끝난 기업들이 많다. 공급을 얼마나 잘하느냐가 기업들 간의 사소한 성패를 가를 것으로 보이나, 산업 전반적으로 봤을 때 손해를 보는 기업은 거의 없으리라.”
“나는 엔비디아가 결국 HW적이든 SW적이든 어떤 형태든간에 스토리지 솔루션을 조만간 내놓을 것이라고 본다. 근거로, 이번 ICMS 소개 공식 블로그 글을 보면, NVMe Key-Value Extension에 대한 언급이 뜬금없이 등장한다. 엔비디아에서 NVMe Command Set 수준까지 언급하는건 굉장히 이례적인 것으로, 그 내용은 아래와 같다.
“These crypto and integrity accelerators are designed to be used as part of the KV pipeline, securing and validating KV flows without adding host CPU overhead. By leveraging standard NVMe and NVMe-oF transports, including NVMe KV extensions, ICMS maintains interoperability with standard storage infrastructure while delivering the specialized performance required for KV cache.”
“이걸 복선이라고 바라보면, 조만간 DOCA에 KVS가 공식적으로 Deploy될 수 있다. GPU 서버에서 I/O Issue할 때 File & Block Interface 대신 KV Interface로 더욱 더 SW Stack을 간소화해서 I/O를 보내고, DPU에서 KV Index 관리를 해 완벽한 Disaggregation을 이루는 것이다. 그 이상, KV-SSD 컨셉까지 바라보면 스토리지 업계에서 더더욱 좋은 소식이겠지만, 거기까진 성급한 예상인거 같고, 딱 DPU 기반 KVS를 통해 컴퓨트단 SW Stack 간소화, 이정도를 타겟하고 있을 것 같다. 근래에 엔비디아가 Vast Data와 같은 기업과 협업을 통해 무언가 오버헤드가 분석된게 있지 싶다.”
“암튼, NVIDIA에서 스토리지 솔루션을 내놓을 것 같고, 만약 그렇게 된다면 정말로 NVIDIA는 이제 Processing Unit뿐만 아니라 서버, Rack-Scale Pod, Network, Mini Workstation, Storage까지 데이터센터의 모든 부분을 총괄하는 기업이 될 수도 있을 것이다.”
AI 판 흔들 ‘괴물 스펙’…SK하이닉스 ‘비밀병기’에 관심 폭발 [강해령의 테크앤더시티]
낸드가 각광받으며 HBF에 대한 중요도와 관심도 또한 급격하게 높아지는 요즘.
“최근 SK하이닉스는 세계적 반도체 학회인 전기전자공학자협회(IEEE) 논문을 통해 ‘H3’ 라는 새로운 반도체 콘셉트를 제시했다. H3는 HBM과 HBF를 활용한 하이브리드반도체 구조의 줄임말이다.”
“이 실험에서 엔비디아 최신 GPU인 블랙웰(B200) 칩 옆에 8개의 5세대 HBM(HBM3E)과 8개의 HBF를 놓았다. 이렇게 했더니 전력 대비 연산 성능이 HBM만 있을 때보다 2.69배 개선될 수 있다는 실험 결과를 얻었다.”
“다만 HBF가 현실로 구현되려면 다양한 문제를 해결해야 하는 것으로 알려졌다. 낸드플래시는 저장 용량은 크지만 새로운 데이터를 기록하거나 형태를 바꾸는 쓰기(write) 성능이 느리다는 단점이 있다.”
“하이브리드 구조 데이터를 읽는(read) 곳에만 HBF를 배치한다고 하더라도 KV 캐시는 갈수록 쓰기 성능이 중요하지기 때문에 이 점을 극복할 수 있는 설계 기술이 필요하다. HBF 가장 아래에 있는 베이스 다이의 컨트롤러 성능이 HBM보다 훨씬 더 고도화해야 한다.”
Some thoughts ahead of Nvidia tonight - Gavin Baker
게빈 베이커의 글인데, 역시나 다 공감되는 내용들이다.
나는 계속해서 말하지만 나는 여전히 AI가 갈길이 많이 남았다고 보고, 이는 투자의 있어서도 같은 입장이다.
“엔비디아의 밸류에이션은 ‘버블로 인한 과잉 투자가 다가옴에 따라 엔비디아의 수익이 국지적 고점에 다다르고 있다고 믿는’ 시장의 시각을 반영하는 것으로 볼 수 있습니다. 분명 엔비디아의 주가 자체가 밸류에이션 버블 상태인 것은 아니며, 시장이 우려하는 것은 밸류에이션 버블이 아닌 펀더멘털 버블, 즉 CAPEX의 버블입니다. 만약 시장이 2027 회계연도 이후에도 엔비디아가 한 자릿수 후반의 높은 연평균 매출 성장률(CAGR)을 기록할 것이라는 확신을 갖게 된다면, 이는 그들의 밸류에이션에 긍정적인 영향을 미칠 것입니다.”
“이번에는 다르다고 믿는 것은 위험하지만, 저는 이번에는 정말 다를 수 있다고 생각합니다. 전 세계는 근본적으로 전력과 웨이퍼 부족에 시달리고 있으며, 이를 해결하는 데 수년이 걸릴 수 있습니다. 이러한 전력과 웨이퍼의 부족이 과잉 투자를 방지할 수도 있습니다. 하이퍼스케일러들은 할 수만 있다면 과잉 투자를 하겠지만, 그들은 그럴 수가 없습니다. 제가 알기로 앞서 언급된 과거 기술들의 도입을 가로막는 이와 비슷한 물리적 부족 현상은 없었습니다. 과잉 투자가 없다면 폭락도 일어나기 어렵습니다. 특히 기술주들이 필수소비재와 동일한 배수로 거래되는 현재의 밸류에이션 수준에서는 더욱 그렇습니다.”
“GPU의 대여 가격은 토큰의 경제적 가치를 반영합니다. GPU 대여 가격은 “AI에 대한 투자 수익률(ROI)”의 심장 박동과도 같습니다. 우리는 능력이 뛰어나고 효율적인 GPU가 지속적으로 출시됨에 따라 AI의 ROI가 매우 긍정적이더라도 대여 가격은 시간이 지남에 따라 하락하는 추세를 보일 것으로 예상해야 합니다. 하지만 놀랍게도 거의 4년이 된 H100의 대여 가격이 지난 2개월 동안 수직 상승했는데, 이는 에이전틱 AI(agentic AI), 특히 에이전틱 코딩이 상당한 경제적 가치를 제공하고 있음을 시사합니다.”
#핀테크
Stripe’s 2025 annual letter
현재의 스트라이프는 에이전트 경제에 진심이다. 그리고 스트라이프가 준비 중인 메인넷 Tempo의 런칭이 머지 않았다.
“크립토 윈터일지 모르지만, 스테이블코인은 썸머를 맞이하고 있습니다. 지난 10년간 스테이블코인의 거래량은 가상자산 가격의 등락을 따라가는 경향이 있었지만, 작년에는 분명한 탈동조화(divergence) 현상이 나타났습니다. 2025년 비트코인 가격은 급락하여 현재 10월 대비 50% 하락한 상태지만, 스테이블코인의 결제 규모는 약 4,000억 달러로 두 배 증가했으며 이 중 60%는 B2B 결제인 것으로 추산됩니다. 당사가 인수한 스테이블코인 오케스트레이션 플랫폼인 브릿지(Bridge)의 거래량 역시 4배 이상 증가했습니다. 실물 경제에서의 도입이 빠르게 진행됨에 따라, 스테이블코인 결제는 조용하지만 거침없이 발전하고 있습니다.”
“당사는 스테이블코인이 대규모로 채택되는 세상에 대비하며, 작년 한 해 동안 블록체인에 대해 깊이 고민했습니다. 오늘날의 블록체인은 트레이딩과 디파이를 위해 설계되었기 때문에 결제에 필수적인 요소(처리량, 신뢰성, 비용 예측 가능성, 개인정보 보호 등)는 크게 주목받지 못했습니다. 비트코인은 초당 10건 미만의 거래를 처리합니다. 작년에는 한 주요 블록체인에서 일어난 밈코인 거래 광풍으로 인해, 한 브릿지 사용자의 대금 지급이 12시간 이상 지연되고 건당 거래 수수료가 35배나 치솟는 일도 있었습니다. 이러한 운영상의 문제는 이미 심각한 수준이지만, 앞으로 거래 수요가 크게 증가할 것으로 예상됨에 따라 상황은 더욱 심화될 것입니다. 당사의 관점에서는 머지않아 AI 에이전트가 대부분의 인터넷 거래를 담당하게 될 가능성이 높으며, 이에 따라 초당 100만 건, 심지어 10억 건 이상의 거래를 지원하는 블록체인이 필요해질 것입니다.“
지난 9월, 당사는 패러다임(Paradigm)과 함께 인큐베이팅하여 결제 전용으로 구축된 블록체인인 ‘템포(Tempo)’를 공개했습니다. 기업들은 템포를 통해 전용 결제 레인, 1초 미만의 거래 완결성, 선택적 개인정보 보호, 그리고 규제 준수 및 회계 시스템과의 상호 운용성을 얻을 수 있습니다. 이러한 기능들이 평범하게 들릴지 모르지만, 실물 경제 활동을 지원하는 인프라에 있어서는 대단히 중요합니다. 비자(Visa), 누뱅크(Nubank), 쇼피파이(Shopify) 같은 기업들은 이미 글로벌 대금 지급, 임베디드 금융, 송금 등 다양한 사용 사례에 대해 템포를 테스트하고 있습니다. 한때 CEO 스스로 가상자산 회의론자라고 밝혔던 클라르나(Klarna)는 브릿지의 ‘오픈 발행(Open Issuance)’ 기능을 사용해 국경 간 결제를 더 빠르고 저렴하게 처리함으로써, 템포 테스트넷에서 스테이블코인을 출시한 최초의 은행이 되었습니다. 또한 템포의 아키텍처는 에이전트 기반 결제(agentic payments)와 소액 결제(microtransactions)에도 매우 적합합니다. 템포의 메인넷이 곧 출시될 예정이며, 야심 찬 기업들이 이를 활용해 어떤 비즈니스를 구축해 나갈지 무척 기대됩니다.
Circle Internet Group, Inc. - Circle Internet Group Q4 2025 Earnings Call
최근 써클의 실적발표에서도 AI 에이전트에 대한 가능성이 강조되었다.
우리는 변곡점에 서 있습니다. 인터넷은 정보를 이동시키는 단계에서 가치를 이동시키는 단계로 진화하고 있습니다. 블록체인, 스테이블코인, 그리고 AI는 별개의 트렌드가 아닙니다. 이들은 인터넷 상에서 기본적으로 구축되어 새롭게 재구성된 글로벌 경제 시스템이라는 훨씬 더 거대한 무언가로 수렴되고 있습니다. 제 견해로는, 수십억 또는 수천억 개의 AI 에이전트가 인터넷을 통해 상호작용하고 경제적 기능을 수행하는 세상에 진입하고 있습니다. 이를 수행하기 위해서는 프로그래밍 가능한 디지털 달러와 개방형 인프라가 필요할 것이며, 그것이 바로 우리 써클(Circle)이 구축해 온 것입니다.
써클의 4분기 실적은 이것이 더 이상 단순한 비전이 아님을 보여줍니다. 실제로 일어나고 있는 일입니다. USDC의 확장은 계속되었고, 스테이블코인 거래량 점유율은 50%에 육박했으며, 우리의 광범위한 플랫폼은 단순 발행을 넘어 온체인 금융의 인프라 계층으로 크게 확장되었습니다. Arc, CCTP, Circle Payments Network, StableFX. 이 각각은 다음에 올 미래를 위한 초석입니다. 앞으로의 기회는 그 어느 때보다 큽니다. 그리고 우리는 이제 막 시작했을 뿐입니다.
사실, 자율적이고 프로그래밍 방식으로 0.00001달러의 트랜잭션 비용으로 크로스 체인 USDC 트랜잭션을 자동화할 수 있게 해주는 서클 게이트웨이(Circle Gateway)라는 새로운 기능의 테스트넷 릴리즈에 막 들어갔습니다. 이것은 당사의 테스트넷에서 실시간 작동 중이며, 이것이 인터넷에서 에이전트 기반 결제 및 수익화 모델 측면에서 가능하게 할 것들에 대해 매우 기쁩니다. 전 세계 어떤 결제 시스템도 이 작업을 수행할 수 없다고 우리는 믿습니다.
#마지막으로
[GN#346] 취향은 새로운 핵심 역량 - 구현의 시대에서 선택의 시대로 - GeekNews
AI 에이전트의 시대가 본격화되면서 중요해지는 것은? 취향, 그리고 감도.
“얼마 전 OpenAI 공동창업자 Greg Brockman이 “취향은 새로운 핵심 역량이다(Taste is a new core skill)” 라는 트윗을 남겼습니다. 사실 취향은 늘 중요했습니다. 스티브 잡스는 1995년 CBS 인터뷰에서 “결국 모든 것은 취향으로 귀결된다” 고 말했습니다. 최고의 것들에 자신을 노출시키고, 그중 좋은 것을 자신의 작업에 가져오는 능력이라는 의미였습니다. 그는 마이크로소프트의 가장 큰 문제 역시 “취향이 없다”는 점이라고 단언하기도 했습니다.”
“왜 지금 다시 취향일까요? “실력 없음. 취향 없음.” 이라는 글은 LLM 덕분에 누구나 앱을 만들 수 있게 되었지만, 사람들에게 선택받기 위해서는 여전히 ‘취향의 벽’ 을 넘어야 한다고 말합니다. 진입 장벽은 낮아졌지만, 자신의 실력과 감각을 과대평가한 결과물도 함께 늘어났습니다. 구현은 쉬워졌지만, 사용자에게 선택받는 일은 여전히 어렵습니다. 결국 살아남는 소프트웨어는 사람들이 인정하는 최소한의 취향을 충족하는 것들입니다.”
“Andrej Karpathy는 “Highly Bespoke Software” , 즉 초개인화 맞춤형 소프트웨어의 시대가 올 것이라고 이야기합니다. 앱스토어에서 범용 앱을 고르는 대신, LLM 에이전트가 즉석에서 개인 맞춤형 소프트웨어를 만들어주는 흐름입니다. 구현 비용이 급격히 낮아질수록 차별화의 축은 ‘만드는 능력’에서 ‘무엇을 만들지 선택하는 능력’ 으로 이동합니다.”
“결국 사람들의 취향을 정확히 겨냥하는 소프트웨어는 더 강해질 것이고, 반복적이고 자잘한 구현은 점점 LLM에 흡수될 가능성이 큽니다. 구현은 평준화되고, 판단은 더 중요해집니다.”
“그렇다면 취향은 어떻게 기를 수 있을까요? 잡스의 인터뷰에는 힌트가 있습니다. 취향은 타고나는 재능이 아니라, 좋은 것에 오래 노출되는 습관에서 만들어집니다. 그는 캘리그래피 수업, 바우하우스 디자인, 음악과 인문학에 대한 몰입을 이야기했습니다. 기술만 아는 사람이 아니라, 폭넓은 문화적 경험을 가진 사람이 되라는 메시지였습니다.”
“Paul Graham은 2002년 “Taste for Makers” 에서 좋은 취향은 좋은 것을 많이 보고, 형편없는 것을 직접 만들어보고, 그것이 형편없다는 사실을 인지하는 과정에서 생긴다고 했습니다. 부끄러움을 느낄 수 있는 감각이 바로 취향의 출발점이라는 뜻입니다.”
“LLM이 코드를 대신 써주더라도, 어떤 것을 선택하고 무엇을 남길지 결정하는 일에는 여전히 취향이 필요합니다. 취향은 하루아침에 생기지 않습니다. 좋은 것을 많이 보고, 직접 만들어보며 실패를 겪고, 무엇이 부족했는지 분석하는 과정에서 취향이 자라납니다. 그렇게 쌓인 취향은 점점 더 잘 버리게 만들고, 결국 만들기 전부터 걸러내는 자신만의 취향으로 이어집니다.”
“이제는 누구나 많이 만들 수 있는 시대입니다. 그래서 더 중요해지는 것은 얼마나 많이 만들어봤는가가 아니라, 얼마나 많이 버려봤는가일지도 모릅니다. 더 많이 만들고, 더 엄격한 취향으로 과감히 버려보시기 바랍니다.”